for epoch in range(start_epoch, start_epoch + epochs):
print('\n\n\nEpoch: {}\n<Train>'.format(epoch))
net.train(True)
loss = 0
learning_rate = learning_rate * (0.5 ** (epoch // 4))
for param_group in optimizer.param_groups:
param_group["learning_rate"] = learning_rate
torch.set_grad_enabled(True)
for idx, (inputs, targets, paths) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
if type(outputs) == tuple:
outputs = outputs[0]
batch_loss = dice_coef(outputs, targets)
optimizer.zero_grad()
batch_loss.backward()
optimizer.step()
loss += float(batch_loss)
progress_bar(idx, len(trainloader), 'Loss: %.5f, Dice-Coef: %.5f'
% ((loss / (idx + 1)), (1 - (loss / (idx + 1)))))
log_msg = '\n'.join(['Epoch: %d Loss: %.5f, Dice-Coef: %.5f' \
% (epoch, loss / (idx + 1), 1 - (loss / (idx + 1)))])
logging.info(log_msg)
def dice_coef(preds, targets, backprop=True):
smooth = 1.0
class_num = 2
if backprop:
for i in range(class_num):
pred = preds[:,i,:,:]
target = targets[:,i,:,:]
intersection = (pred * target).sum()
loss_ = 1 - ((2.0 * intersection + smooth) / (pred.sum() + target.sum() + smooth))
if i == 0:
loss = loss_
else:
loss = loss + loss_
loss = loss/class_num
return loss
else:
# Need to generalize
targets = np.array(targets.argmax(1))
if len(preds.shape) > 3:
preds = np.array(preds).argmax(1)
for i in range(class_num):
pred = (preds==i).astype(np.uint8)
target= (targets==i).astype(np.uint8)
intersection = (pred * target).sum()
loss_ = 1 - ((2.0 * intersection + smooth) / (pred.sum() + target.sum() + smooth))
if i == 0:
loss = loss_
else:
loss = loss + loss_
loss = loss/class_num
return loss
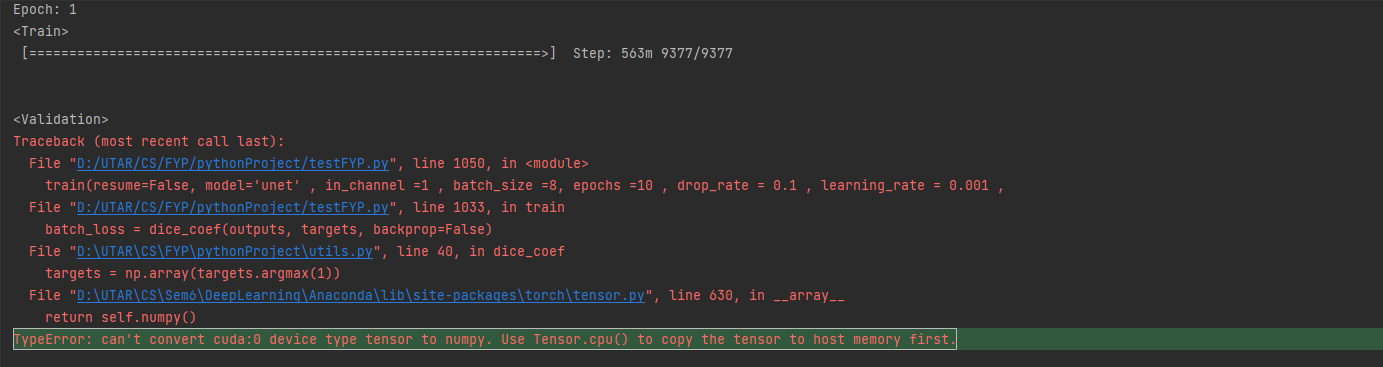
I facing this type of error anyone knows how to solve it?