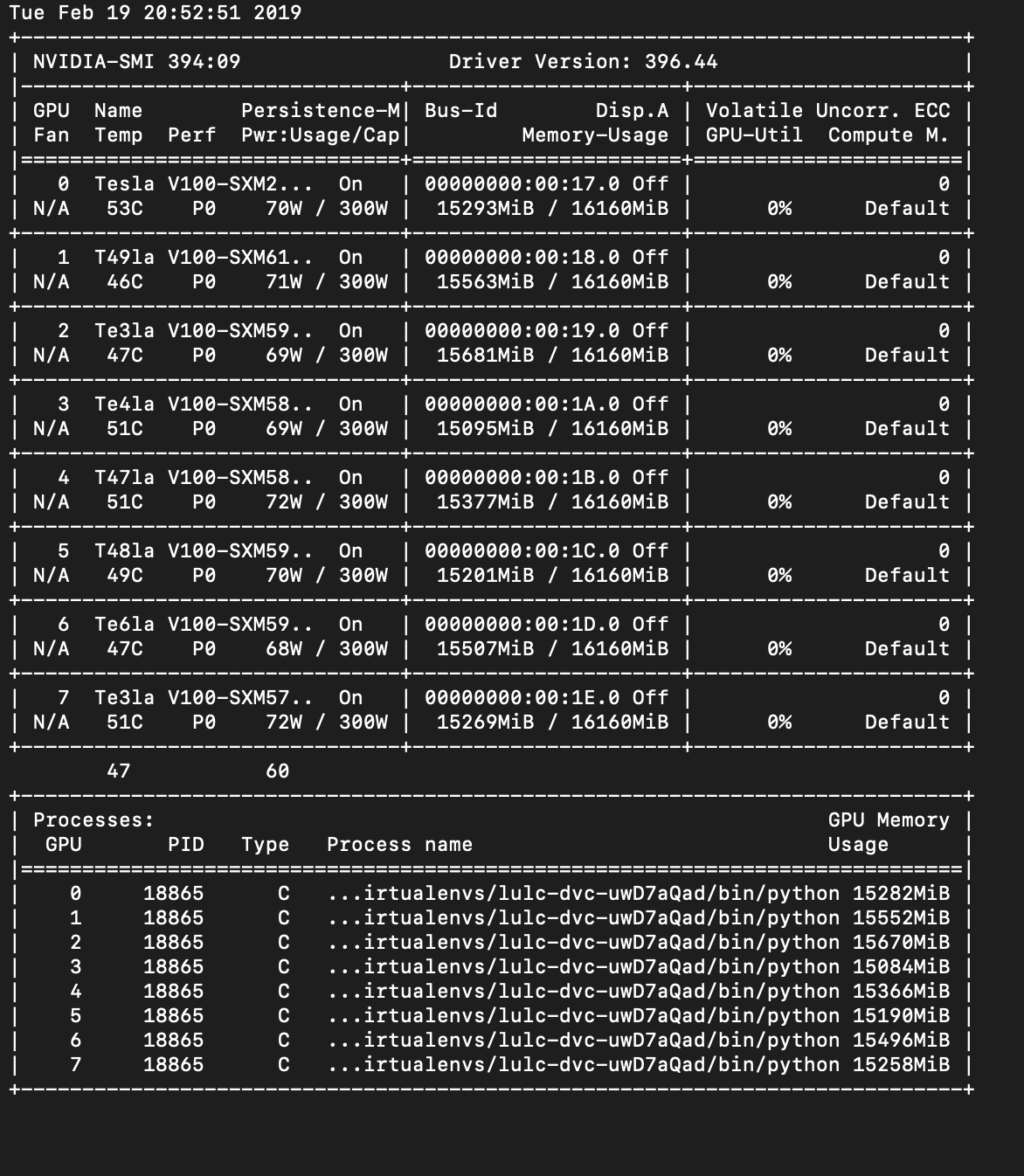
I got lucky today and found a way to get near-equal utilization across GPUs.
The two main changes were:
-
Make sure my outer-most module is wrapped by DataParallel. Before I had an inner module (like a layer) wrapped only.
From:
class BundledNet(nn.Module): def __init__(self, net, preproc=None): self.net = net if torch.cuda.device_count() > 1: self.net = torch.nn.DataParallel(self.net) self.preproc = preproc def forward(self, x): if self.preproc != None: x = self.preproc(x) x = self.net(x) return x net = BundledNet(ResNet(), preproc=resnet_norm)To:
class BundledNet(nn.Module): def __init__(self, net, preproc=None): self.net = net self.preproc = preproc def forward(self, x): if self.preproc != None: x = self.preproc(x) x = self.net(x) return x net = BundledNet(ResNet(), preproc=resnet_norm) if torch.cuda.device_count() > 1: net = torch.nn.DataParallel(net)It appears that the preprocessing and post-processing in the forward pass of
BundledNetwas enough to cause an imbalance across the GPUs. -
Compute my loss function inside a DataParallel module.
From:
loss = torch.nn.CrossEntropyLoss()To:
loss = torch.nn.CrossEntropyLoss() if torch.cuda.device_count() > 1: loss = CriterionParallel(loss)Given:
class ModularizedFunction(torch.nn.Module): """ A Module which calls the specified function in place of the forward pass. Useful when your existing loss is functional and you need it to be a Module. """ def __init__(self, forward_op): super().__init__() self.forward_op = forward_op def forward(self, *args, **kwargs): return self.forward_op(*args, **kwargs) class CriterionParallel(torch.nn.Module): def __init__(self, criterion): super().__init__() if not isinstance(criterion, torch.nn.Module): criterion = ModularizedFunction(criterion) self.criterion = torch.nn.DataParallel(criterion) def forward(self, *args, **kwargs): """ Note the .mean() here, which is required since DataParallel gathers any scalar outputs of forward() into a vector with one item per GPU (See DataParallel docs). """ return self.criterion(*args, **kwargs).mean()
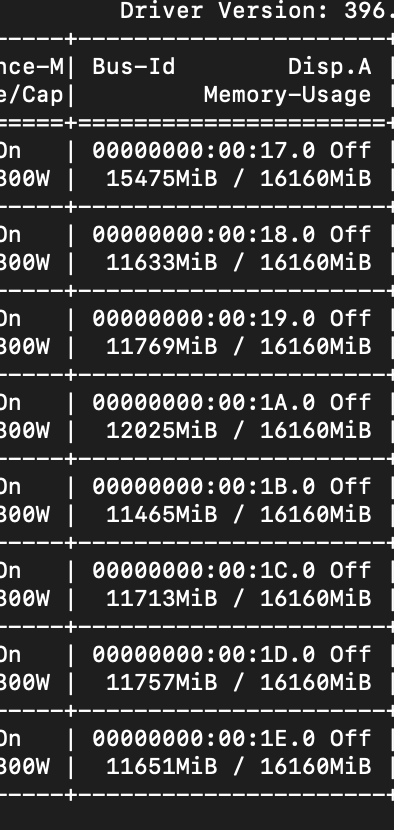
The general rule seems to be that you should try not to do any cuda tensor computation whatsoever outside the forward pass of a DataParallel module. Outside of a DataParallel module, I am only passing tensors around and moving them on and off the GPU. See this before/after image of nvidia-smi to see the results:
Before:
After: