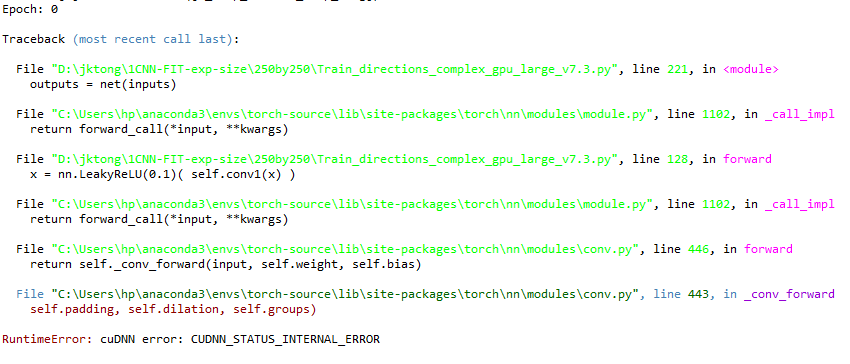
OK, the network and parameter updating process is defined as follows:
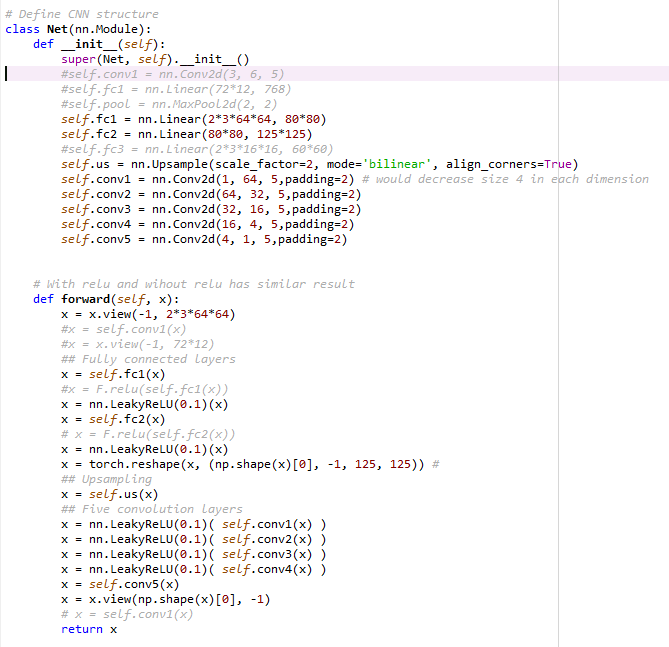
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#self.conv1 = nn.Conv2d(3, 6, 5)
#self.fc1 = nn.Linear(72*12, 768)
#self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(2*3*64*64, 80*80)
self.fc2 = nn.Linear(80*80, 125*125)
#self.fc3 = nn.Linear(2*3*16*16, 60*60)
self.us = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv1 = nn.Conv2d(1, 64, 5,padding=2) # would decrease size 4 in each dimension
self.conv2 = nn.Conv2d(64, 32, 5,padding=2)
self.conv3 = nn.Conv2d(32, 16, 5,padding=2)
self.conv4 = nn.Conv2d(16, 4, 5,padding=2)
self.conv5 = nn.Conv2d(4, 1, 5,padding=2)
# With relu and wihout relu has similar result
def forward(self, x):
x = x.view(-1, 2*3*64*64)
#x = self.conv1(x)
#x = x.view(-1, 72*12)
## Fully connected layers
x = self.fc1(x)
#x = F.relu(self.fc1(x))
x = nn.LeakyReLU(0.1)(x)
x = self.fc2(x)
# x = F.relu(self.fc2(x))
x = nn.LeakyReLU(0.1)(x)
x = torch.reshape(x, (np.shape(x)[0], -1, 125, 125)) #
## Upsampling
x = self.us(x)
## Five convolution layers
x = nn.LeakyReLU(0.1)( self.conv1(x) )
x = nn.LeakyReLU(0.1)( self.conv2(x) )
x = nn.LeakyReLU(0.1)( self.conv3(x) )
x = nn.LeakyReLU(0.1)( self.conv4(x) )
x = self.conv5(x)
x = x.view(np.shape(x)[0], -1)
# x = self.conv1(x)
return x
#Generate model
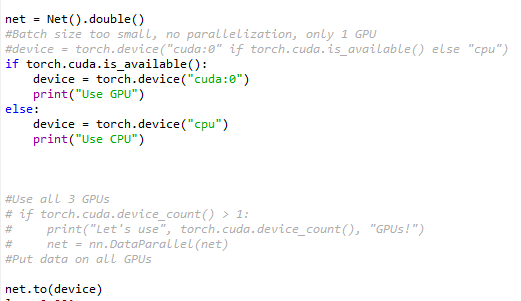
net = Net().double()
#Batch size too small, no parallelization, only 1 GPU
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
device = torch.device("cuda:0")
print("Use GPU")
else:
device = torch.device("cpu")
print("Use CPU")
#Use all 3 GPUs
# if torch.cuda.device_count() > 1:
# print("Let's use", torch.cuda.device_count(), "GPUs!")
# net = nn.DataParallel(net)
#Put data on all GPUs
net.to(device)
#Learning Process
# Train the network
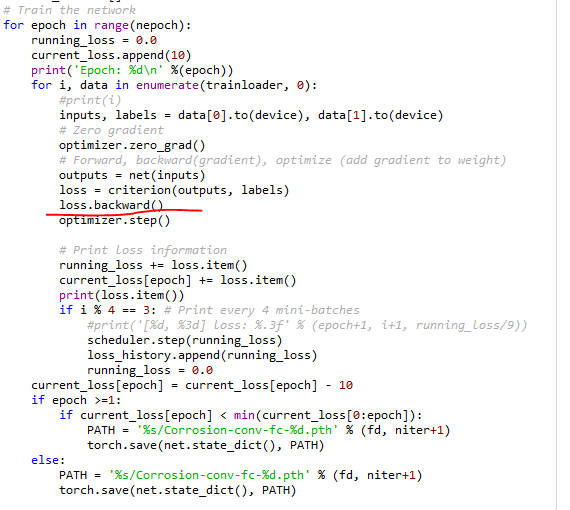
for epoch in range(nepoch):
running_loss = 0.0
current_loss.append(10)
print('Epoch: %d\n' %(epoch))
for i, data in enumerate(trainloader, 0):
#print(i)
inputs, labels = data[0].to(device), data[1].to(device)
# Zero gradient
optimizer.zero_grad()
# Forward, backward(gradient), optimize (add gradient to weight)
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Print loss information
running_loss += loss.item()
current_loss[epoch] += loss.item()
print(loss.item())
if i % 4 == 3: # Print every 4 mini-batches
#print('[%d, %3d] loss: %.3f' % (epoch+1, i+1, running_loss/9))
scheduler.step(running_loss)
loss_history.append(running_loss)
running_loss = 0.0
current_loss[epoch] = current_loss[epoch] - 10
if epoch >=1:
if current_loss[epoch] < min(current_loss[0:epoch]):
PATH = '%s/Corrosion-conv-fc-%d.pth' % (fd, niter+1)
torch.save(net.state_dict(), PATH)
else:
PATH = '%s/Corrosion-conv-fc-%d.pth' % (fd, niter+1)
torch.save(net.state_dict(), PATH)
Shape of input tensors:
inputs: torch.Size([64,2,3,64,64])
labels: torch.Size([64,62500])
when it runs to outputs = net(inputs), the error occured