I’m working on a classification problem (500 classes). My NN has 3 fully connected layers, followed by an LSTM layer. I use nn.CrossEntropyLoss() as my loss function. This is my network’s configuration
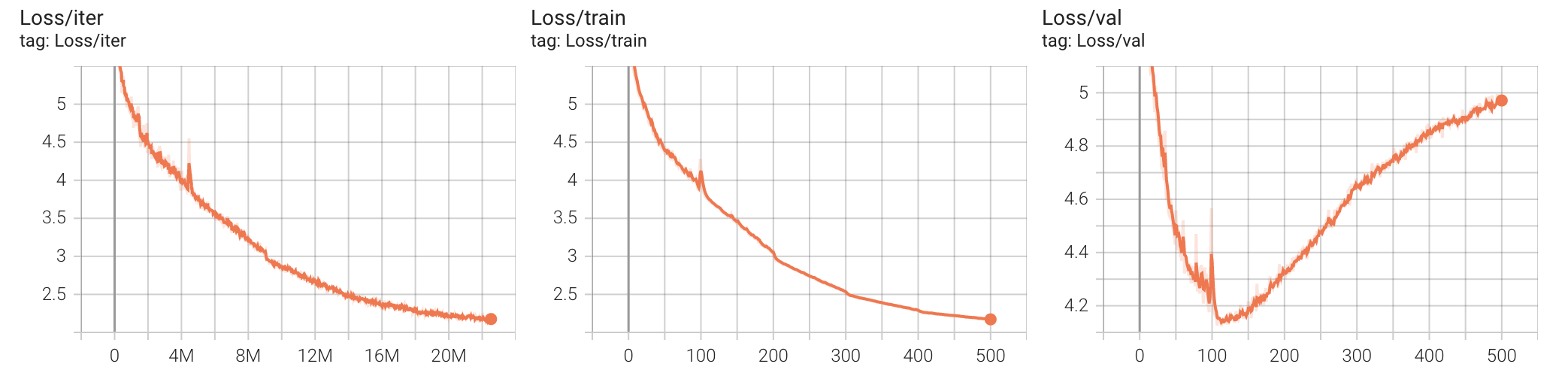
This is what my loss looks like. It increases after reaching a particular value no matter what setting I use. I’ve used k-fold cross–validation but the loss/accuracy across all folds stays the same, so I’m assuming that there’s no issue in the distribution of train/val splits.
Note that 500 classes is a fairly large number. It is reasonable to expect
that you might need a large amount of training data to train effectively.
The graphs you posted show your training loss continuing to go down while
your validation loss turns around and starts going up. This is a typical sign
of overfitting.
The best way to avoid / reduce overfitting is to train with more data. If
you simply don’t have more training data it can be helpful to use data
augmentation. What you do is make some “synthetic” training data by
modifying copies of your real training data. It’s worth a try.
If data augmentation doesn’t work, the next step is to make your model
simpler (reduce its “capacity”). You can make your model narrower or
shallower or both. The basic idea is that the more complicated your model
is, the more parameters it has with which to overfit – that is to learn specific
details of your training data that aren’t actually relevant to the general
problem you are trying to solve. In effect, your model “memorizes” the
correct answers (predictions) for the specific samples in your training
set without really learning how to make predictions for out-of-sample
data. Hence the higher loss for your validation set (that you didn’t train
with).
Using a learning-rate scheduler could well help you train more efficiently on your training set, but it won’t address the overfitting problem.
Dropout can help prevent overfitting. But you say that it’s not working for
you, so your best approach will be to acquire more training data. Barring
that, data augmentation is worth a shot.
You could also try simplifying your model, but there is the risk that if you
make your model too simple, it won’t have enough structure to be able to
learn what sounds like a potentially challenging (500 classes) classification
problem.
This comes back to my original comment – harder problems require more
training data.
@KFrank After adding more training data, the validation loss plateaus at of 3.2 (lower than the previous case). What could be the possible cause for this? How can the loss be driven further down?
You can’t magically lower the validation loss – training, by definition, lowers
the training loss.
When your validation loss plateaus, is the training loss still going down? If
so, you might be seeing the beginning of overfitting. (If you are overfitting,
see my comments posted above.)
If the training loss has plateaued, you need to focus on figuring out how
to train so as to further lower your training loss (and see whether that also
lowers your validation loss).
First, try training (much) longer. Complicated models do sometimes get
“stuck” in plateaus, but then sometimes get “unstuck” after (a lot) more
training.
Experiment with momentum and various optimizers, and, as you’ve already
tried, with learning-rate schedulers. Oddly enough, lowering your learning
rate can sometimes let you “sneak” out of a plateau while increasing your
learning rate can sometimes “jolt” you out of a plateau.
You don’t say how many epochs you’ve tried training with, but the graph
you posted suggests that you’ve used 500 epochs. That’s really not a lot,
especially for complicated problems (and lots of training data). You might
just need to be patient and experiment with training a lot more.
@KFrank
I tried adding more data and training longer. Previously, the number of data points was 3k and now there are 66k. I’m now training for 1500 epochs instead of 500 (before) with a very low learning rate (1e-5, before 6.4e-4). This is how the loss plots look like
Your validation loss is still going down (as is your training loss), so there is
likely more to be gained (and you haven’t started overfitting yet).
I’ve never experimented with long-short-term-memory models, but, in general
for real models running on real problems, 1500 epochs is a very small number.
Also, try experimenting with various optimizers and their hyperparameters, as
well as with the learning rate.