Hi, Pytorch community,
I’m writing a customized pipeline parallelism for a customized model, and I’ve been troubled by a memory leak problem for a while.
My device is A100 40G, and the software is official NGC pytorch 23.08. Below is the minimum demo to reproduce the problem.
import os
import torch
import torch.distributed as dist
from torch.autograd.variable import Variable
def _kernel_make_viewless_tensor(inp, requires_grad):
'''Make a viewless tensor.
View tensors have the undesirable side-affect of retaining a reference
to the originally-viewed tensor, even after manually setting the '.data'
field. This method creates a new tensor that links to the old tensor's
data, without linking the viewed tensor, referenced via the '._base'
field.
'''
out = torch.empty((1,), dtype=inp.dtype, device=inp.device, requires_grad=requires_grad,)
out.data = inp.data
return out
class MakeViewlessTensor(torch.autograd.Function):
'''
Autograd function to make a viewless tensor.
This function should be used in cases where the computation graph needs
to be propagated, but we only want a viewless tensor (e.g.,
ParallelTransformer's hidden_states). Call this function by passing
'keep_graph = True' to 'make_viewless_tensor()'.
'''
@staticmethod
def forward(ctx, inp, requires_grad):
return _kernel_make_viewless_tensor(inp, requires_grad)
@staticmethod
def backward(ctx, grad_output):
return grad_output, None
def make_viewless_tensor(inp, requires_grad, keep_graph):
'''
Entry-point for creating viewless tensors.
This method should be used, rather than calling 'MakeViewlessTensor'
or '_kernel_make_viewless_tensor' directly. This method acts as a
switch for determining if an autograd function or a regular method
should be used to create the tensor.
'''
# return tensor as-is, if not a 'view'
if inp._base is None:
return inp
# create viewless tensor
if keep_graph:
return MakeViewlessTensor.apply(inp, requires_grad)
else:
return _kernel_make_viewless_tensor(inp, requires_grad)
class Model(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.fc1 = torch.nn.Linear(1024, 4096)
self.fc2 = torch.nn.Linear(4096, 2048)
def forward(self, x):
y = self.fc1(x)
z = self.fc2(y)
z = make_viewless_tensor(z, requires_grad=True, keep_graph=True)
return y, z
class Context:
def __init__(self):
self.input_tensors = [[], []]
self.output_tensors = [[], []]
self.grad_tensors = [None, None]
self.reqs = [[], []]
def _communicate(self, recv_shapes=None, src_ranks=None,
send_tensors=None, tgt_ranks=None):
ops, ret = [], []
device=torch.cuda.current_device() if torch.cuda.is_available() else None
if send_tensors is not None:
assert len(send_tensors) == len(tgt_ranks)
for tensor, tgt in zip(send_tensors, tgt_ranks):
ops.append(dist.P2POp(dist.isend, tensor, tgt))
if recv_shapes is not None:
assert len(recv_shapes) == len(src_ranks)
for shape, src in zip(recv_shapes, src_ranks):
buf = torch.empty(
shape, requires_grad=True,
dtype=torch.half, device=device)
ops.append(dist.P2POp(dist.irecv, buf, src))
ret.append(buf)
reqs = dist.batch_isend_irecv(ops)
return ret, reqs
def send_input(self, send_tensors, tgt_ranks, idx):
_, reqs = self._communicate(send_tensors=send_tensors, tgt_ranks=tgt_ranks)
self.reqs[idx].extend(reqs)
def recv_input(self, recv_shapes, src_ranks, idx):
inputs, reqs = self._communicate(recv_shapes=recv_shapes, src_ranks=src_ranks)
self.reqs[idx].extend(reqs)
self.input_tensors[idx].append(tuple(inputs))
def get_input(self, idx):
while self.reqs[idx]:
req = self.reqs[idx].pop(0)
req.wait()
return self.input_tensors[idx][-1]
def send_output(self, send_tensors, tgt_ranks, idx):
_, reqs = self._communicate(send_tensors=send_tensors, tgt_ranks=tgt_ranks)
self.reqs[idx].extend(reqs)
self.output_tensors[idx].append(tuple(send_tensors))
def recv_output(self, recv_shapes, src_ranks, idx):
outputs, reqs = self._communicate(recv_shapes=recv_shapes, src_ranks=src_ranks)
self.reqs[idx].extend(reqs)
self.output_tensors[idx].append(tuple(outputs))
def recv_output_grad(self, recv_shapes, src_ranks, idx):
grads, reqs = self._communicate(recv_shapes=recv_shapes, src_ranks=src_ranks)
self.reqs[idx].extend(reqs)
self.grad_tensors[idx] = grads
def get_output_grad(self, idx):
while self.reqs[idx]:
req = self.reqs[idx].pop(0)
req.wait()
grads = self.grad_tensors[idx]
self.grad_tensors[idx] = None
return grads
def pop_input(self, idx):
return self.input_tensors[idx].pop()
def pop_output(self, idx):
return self.output_tensors[idx].pop()
def send_output_grad(self, send_tensors, tgt_ranks, idx):
_, reqs = self._communicate(send_tensors=send_tensors, tgt_ranks=tgt_ranks)
self.reqs[idx].extend(reqs)
def check_clean(self):
assert len(self.input_tensors[0]) == 0
assert len(self.input_tensors[1]) == 0
assert len(self.output_tensors[0]) == 0
assert len(self.output_tensors[1]) == 0
assert len(self.reqs[0]) == 0
assert len(self.reqs[1]) == 0
assert self.grad_tensors[0] is None
assert self.grad_tensors[1] is None
def backward_step(input_tensors, output_tensors, output_grads):
#torch.autograd.backward(output_tensors, output_grads)
Variable._execution_engine.run_backward(
tensors=tuple(output_tensors),
grad_tensors=tuple(output_grads),
keep_graph=False,
create_graph=False,
inputs=tuple(),
allow_unreachable=True,
accumulate_grad=True,
)
input_tensor_grads = []
for each in input_tensors:
if each is None or not each.is_leaf:
input_tensor_grads.append(None)
else:
input_tensor_grads.append(each.grad)
return input_tensor_grads
def main():
rank = dist.get_rank()
is_cuda = torch.cuda.is_available()
device = torch.cuda.current_device() if is_cuda else None
context = Context()
input_shapes = [[32, 512, 1024]]
output_shapes = [[32, 512, 4096], [32, 512, 2048]]
if rank == 0:
if is_cuda:
torch.cuda.memory._record_memory_history()
model = Model().half().cuda() # 8+16M
# get 2 inputs
context.recv_input(input_shapes, src_ranks=[1, ], idx=0) # 32M
context.recv_input(input_shapes, src_ranks=[1, ], idx=1) # 32M
# forward pass 0
(inp,) = context.get_input(idx=0)
y, z = model(inp) # 128 + 64M
context.send_output((y, z), tgt_ranks=[1, 1], idx=0)
#assert z._base is None
#z.data = torch.empty((1,), device=z.device, dtype=z.dtype,)
# forward pass 1
(inp,) = context.get_input(idx=1)
y, z = model(inp) # 128 + 64M
context.send_output((y, z), tgt_ranks=[1, 1], idx=1)
#assert z._base is None
#z.data = torch.empty((1,), device=z.device, dtype=z.dtype,)
# clean reqs
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
# get output grad
context.recv_output_grad(recv_shapes=output_shapes, src_ranks=[1, 1], idx=0) # 128 + 64M
context.recv_output_grad(recv_shapes=output_shapes, src_ranks=[1, 1], idx=1) # 128 + 64M
# backward pass 1
dy, dz = context.get_output_grad(idx=0)
inp = context.pop_input(idx=0)
oup = context.pop_output(idx=0)
inp_grad = backward_step(inp, oup, (dy, dz))
# del inp
# del oup
# del dy
# del dz
# torch.cuda.empty_cache()
# backward pass 2
dy, dz = context.get_output_grad(idx=1)
inp = context.pop_input(idx=1)
oup = context.pop_output(idx=1)
inp_grad = backward_step(inp, oup, (dy, dz))
# del inp
# del oup
# del dy
# del dz
context.check_clean()
a = torch.rand(4096, 2048)
b = torch.rand(2048, 4096)
c = torch.matmul(a, b)
model.zero_grad()
torch.cuda.synchronize()
if is_cuda:
torch.cuda.memory._dump_snapshot("custom")
else:
x1 = torch.rand(input_shapes[0], dtype=torch.half, device=device)
x2 = torch.rand(input_shapes[0], dtype=torch.half, device=device)
context.send_input((x1, ), [0,], idx=0)
context.send_input((x2, ), [0,], idx=1)
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
context.recv_output(recv_shapes=output_shapes, src_ranks=[0, 0], idx=0)
context.recv_output(recv_shapes=output_shapes, src_ranks=[0, 0], idx=1)
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
dy1 = torch.rand(output_shapes[0], dtype=torch.half, device=device)
dy2 = torch.rand(output_shapes[0], dtype=torch.half, device=device)
dz1 = torch.rand(output_shapes[1], dtype=torch.half, device=device)
dz2 = torch.rand(output_shapes[1], dtype=torch.half, device=device)
context.send_output_grad(send_tensors=(dy1, dz1), tgt_ranks=[0, 0], idx=0)
context.send_output_grad(send_tensors=(dy2, dz2), tgt_ranks=[0, 0], idx=1)
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
print(f"rank {rank} done", flush=True)
if __name__ == "__main__":
rank = int(os.getenv('RANK', os.getenv('OMPI_COMM_WORLD_RANK')))
world_size = int(os.getenv("WORLD_SIZE", os.getenv("OMPI_COMM_WORLD_SIZE")))
backend = os.getenv("BACKEND", "nccl")
is_cuda = torch.cuda.is_available()
if backend == 'nccl':
assert is_cuda
dist.init_process_group(
rank=rank, world_size=world_size, backend=backend)
if is_cuda:
local_rank = rank % torch.cuda.device_count()
torch.cuda.set_device(local_rank)
main()
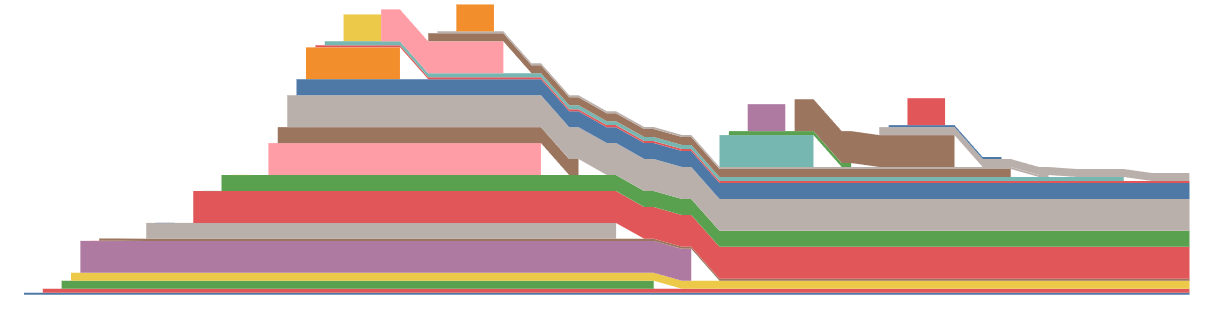
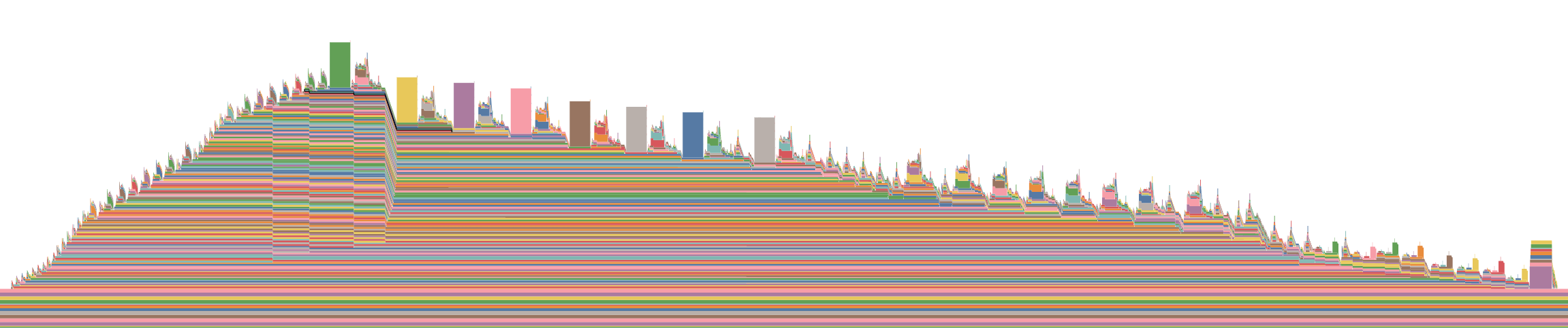
If you run the code snippet, the output memory snapshot looks like this way:

Here, the problem is that the first batch’s input, output and output gradients cannot be released after its backward computation. With more (micro) batches, this causes more memory leak and thus OOM.
I suspect this is caused by the interplay of nccl p2p and the misuse of Variable._execution_engine.run_backward, since only the send tensors and the recv buffers are not released properly.
Endeavors I’ve tried:
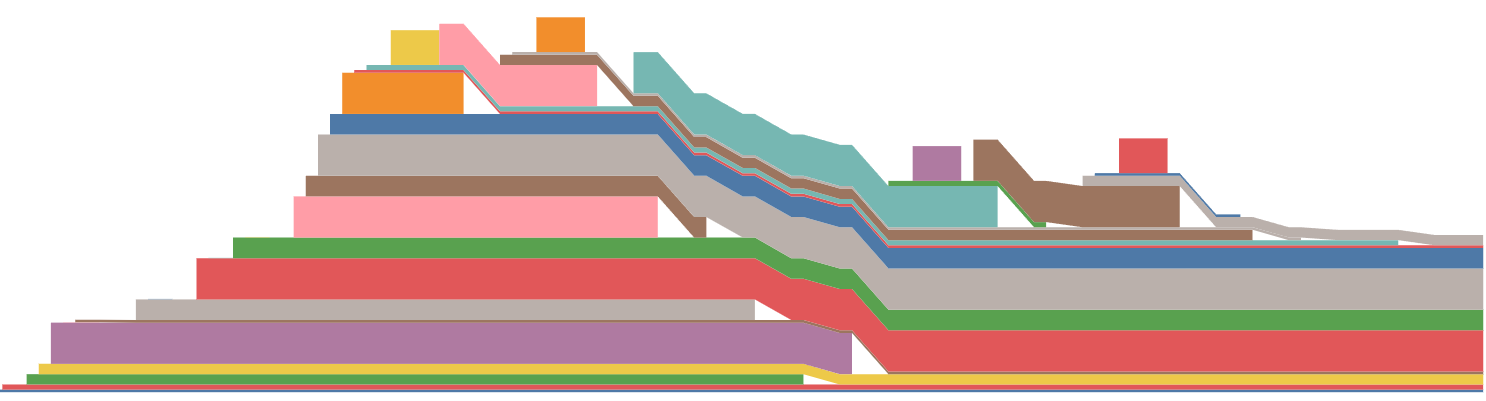
- Switch to
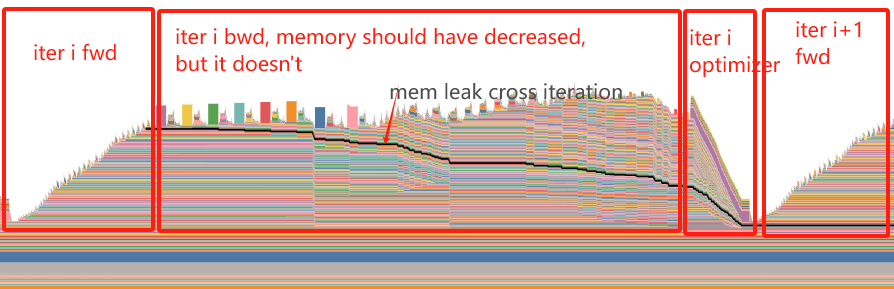
torch.autograd.backward. Unfortunately, it doesn’t work in my real project, it does work for the demo. Here is the memory snapshot:
This is what I expect. The first batch is released. - Set
TORCH_NCCL_AVOID_RECORD_STREAMS=1. Initially, I suspect it is caused by NCCL, so following this: CUDA allocation lifetime for inputs to distributed.all_reduce, I tried the env variable, but it doesn’t work. - Experiment with single output. I use
Variable._execution_engine.run_backwardcopied from Megatron: Megatron-LM/megatron/core/pipeline_parallel/schedules.py at e33c8f78a35765d5aa37475a144da60e8a2349d1 · NVIDIA/Megatron-LM · GitHub, because I expect to release outputs after sending them to other p2p ranks. However, Megatron only outputs a single tensor, while in my customized model, it outputs two tensors, which leads to the memory leak.
Here is the modified code:
class Model(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.fc1 = torch.nn.Linear(1024, 4096)
self.fc2 = torch.nn.Linear(4096, 2048)
def forward(self, x):
y = self.fc1(x)
z = self.fc2(y)
z = make_viewless_tensor(z, requires_grad=True, keep_graph=True)
return z
def main():
rank = dist.get_rank()
is_cuda = torch.cuda.is_available()
device = torch.cuda.current_device() if is_cuda else None
context = Context()
input_shapes = [[32, 512, 1024]]
# output_shapes = [[32, 512, 4096], [32, 512, 2048]]
output_shapes = [[32, 512, 2048]]
if rank == 0:
if is_cuda:
torch.cuda.memory._record_memory_history()
model = Model().half().cuda() # 8+16M
# get 2 inputs
context.recv_input(input_shapes, src_ranks=[1, ], idx=0) # 32M
context.recv_input(input_shapes, src_ranks=[1, ], idx=1) # 32M
# forward pass 0
(inp,) = context.get_input(idx=0)
z = model(inp) # 128 + 64M
context.send_output((z,), tgt_ranks=[1,], idx=0)
#assert z._base is None
#z.data = torch.empty((1,), device=z.device, dtype=z.dtype,)
# forward pass 1
(inp,) = context.get_input(idx=1)
z = model(inp) # 128 + 64M
context.send_output((z,), tgt_ranks=[1,], idx=1)
#assert z._base is None
#z.data = torch.empty((1,), device=z.device, dtype=z.dtype,)
# clean reqs
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
# get output grad
context.recv_output_grad(recv_shapes=output_shapes, src_ranks=[1,], idx=0) # 128 + 64M
context.recv_output_grad(recv_shapes=output_shapes, src_ranks=[1,], idx=1) # 128 + 64M
# backward pass 1
dz = context.get_output_grad(idx=0)
inp = context.pop_input(idx=0)
oup = context.pop_output(idx=0)
inp_grad = backward_step(inp, oup, dz)
# del inp
# del oup
# del dy
# del dz
# torch.cuda.empty_cache()
# backward pass 2
dz = context.get_output_grad(idx=1)
inp = context.pop_input(idx=1)
oup = context.pop_output(idx=1)
inp_grad = backward_step(inp, oup, dz)
# del inp
# del oup
# del dy
# del dz
context.check_clean()
a = torch.rand(4096, 2048)
b = torch.rand(2048, 4096)
c = torch.matmul(a, b)
model.zero_grad()
torch.cuda.synchronize()
if is_cuda:
torch.cuda.memory._dump_snapshot("custom_bwd")
else:
x1 = torch.rand(input_shapes[0], dtype=torch.half, device=device)
x2 = torch.rand(input_shapes[0], dtype=torch.half, device=device)
context.send_input((x1, ), [0,], idx=0)
context.send_input((x2, ), [0,], idx=1)
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
context.recv_output(recv_shapes=output_shapes, src_ranks=[0,], idx=0)
context.recv_output(recv_shapes=output_shapes, src_ranks=[0,], idx=1)
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
# dy1 = torch.rand(output_shapes[0], dtype=torch.half, device=device)
# dy2 = torch.rand(output_shapes[0], dtype=torch.half, device=device)
dz1 = torch.rand(output_shapes[0], dtype=torch.half, device=device)
dz2 = torch.rand(output_shapes[0], dtype=torch.half, device=device)
context.send_output_grad(send_tensors=(dz1,), tgt_ranks=[0,], idx=0)
context.send_output_grad(send_tensors=(dz2,), tgt_ranks=[0,], idx=1)
while context.reqs[0]:
req = context.reqs[0].pop(0)
req.wait()
while context.reqs[1]:
req = context.reqs[1].pop(0)
req.wait()
print(f"rank {rank} done", flush=True)
if __name__ == "__main__":
rank = int(os.getenv('RANK', os.getenv('OMPI_COMM_WORLD_RANK')))
world_size = int(os.getenv("WORLD_SIZE", os.getenv("OMPI_COMM_WORLD_SIZE")))
backend = os.getenv("BACKEND", "nccl")
is_cuda = torch.cuda.is_available()
if backend == 'nccl':
assert is_cuda
dist.init_process_group(
rank=rank, world_size=world_size, backend=backend)
if is_cuda:
local_rank = rank % torch.cuda.device_count()
torch.cuda.set_device(local_rank)
main()
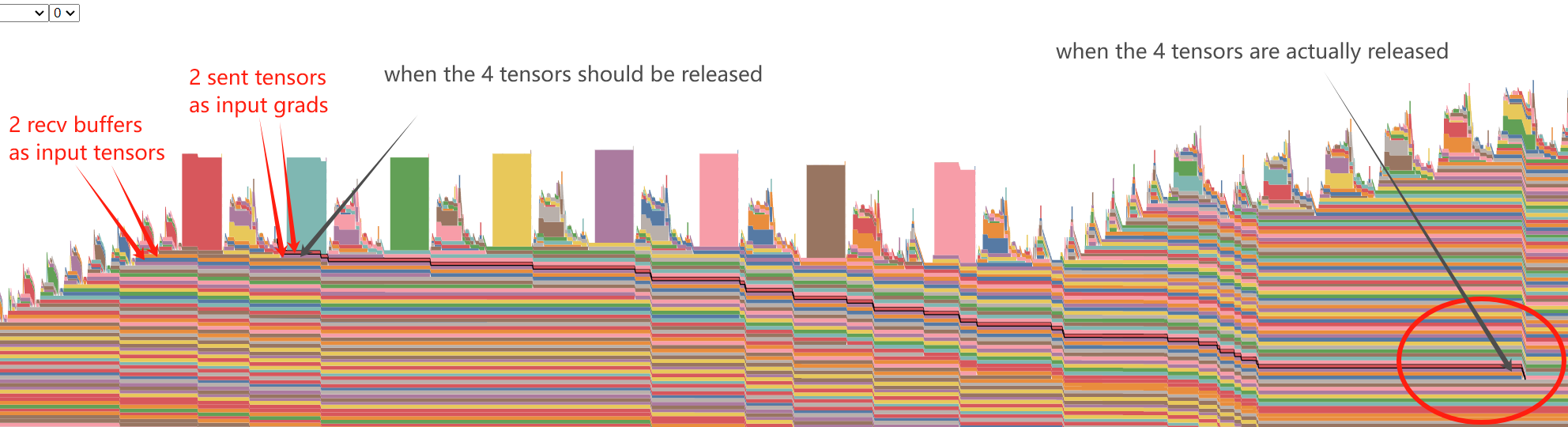
Whether I use Variable._execution_engine.run_backward or torch.autograd.backward, they always work.
Mem snapshot for Variable._execution_engine.run_backward:

Mem snapshot for
torch.autograd.backward: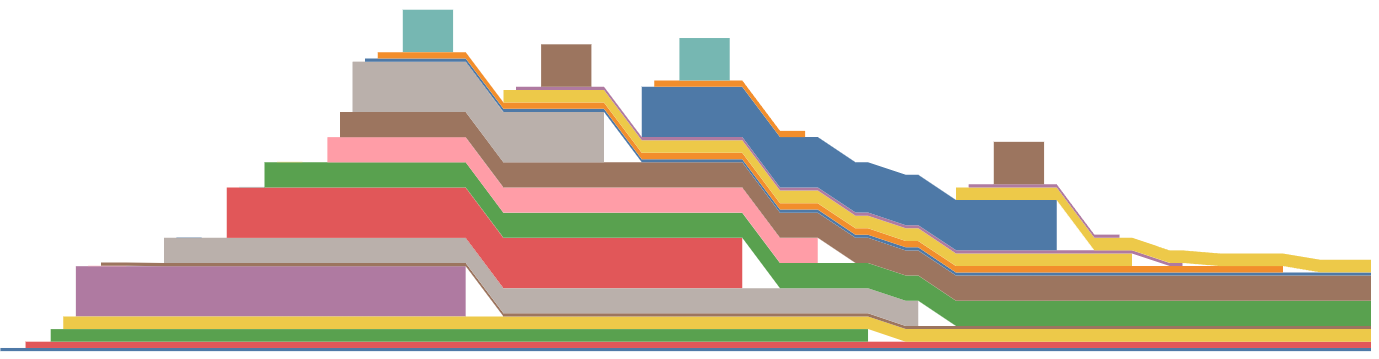
I would really appreciate it if you could let me know how to properly fix the original memory leak.