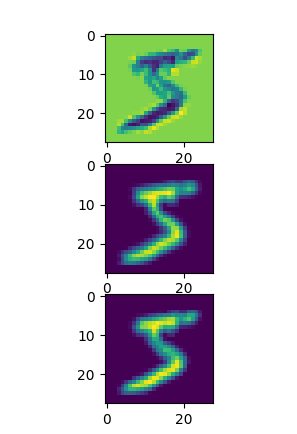
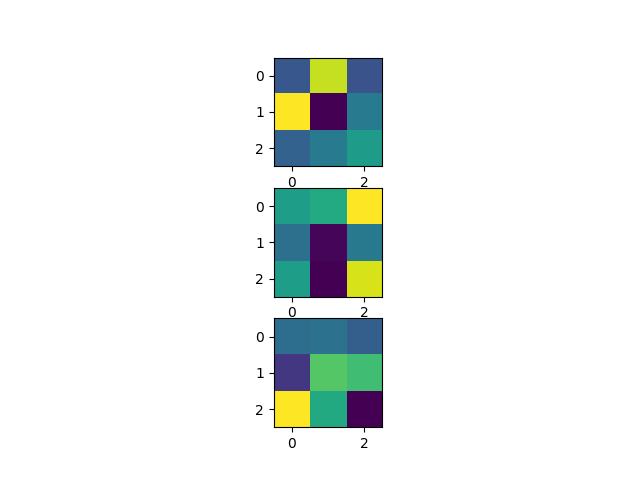Based on your architecture, a decoder could look like this:
class Extractor(nn.Module):
def __init__(self):
super(Extractor, self).__init__()
self.extractor = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=5, stride=1, padding=0),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=5, stride=1, padding=0),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, 5, 2),
nn.ReLU(),
nn.ConvTranspose2d(128, 64, 6, 2),
nn.ReLU(),
nn.ConvTranspose2d(64, 3, 6, 2)
)
def forward(self, x):
x = self.extractor(x)
x = self.decoder(x)
return x
To visualize the activations, you could try the same code as above:
model = Extractor()
model.extractor[0].register_forward_hook(get_activation('ext_conv1'))
x = torch.randn(1, 3, 96, 96)
output = model(x)
print(output.shape)
> torch.Size([1, 3, 96, 96])
act = activation['ext_conv1'].squeeze()
num_plot = 4
fig, axarr = plt.subplots(min(act.size(0), num_plot))
for idx in range(min(act.size(0), num_plot)):
axarr[idx].imshow(act[idx])
I’m just plotting the first 4 maps, so you could just remove num_plot and the min call if you want to plot all maps.