I was wondering what the reason is that weights are initialized the way they are? For torch.nn.Linear the weights are initialized with samples from Uniform(-sqrt(k), sqrt(k)) with k = 1/no_features. Linear — PyTorch 1.7.0 documentation
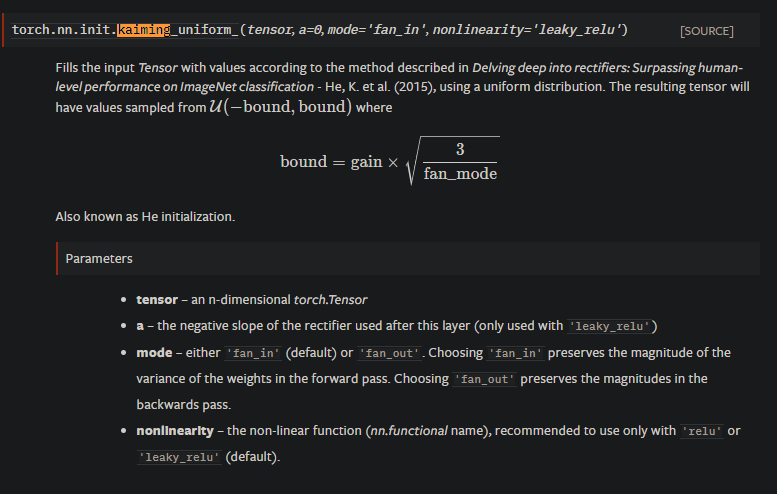
In the source code “kaiming_uniform” appears. However, to my understanding Kaiming He at al. [1] suggest sampling from a normal distribution. If I take the condition they state that 0.5 * no_features * VAR[w_l] = 1 and plug in the variance for the uniform distribution which should be (b - a)^2 / 12, with a= - sqrt(k) and b=sqrt(k), this does not add up either.
So what is the “Kaiming Uniform” and/or what is the reason that the weights are "initialized from initialized from U}(-sqrt(k)), sqrt(k))?
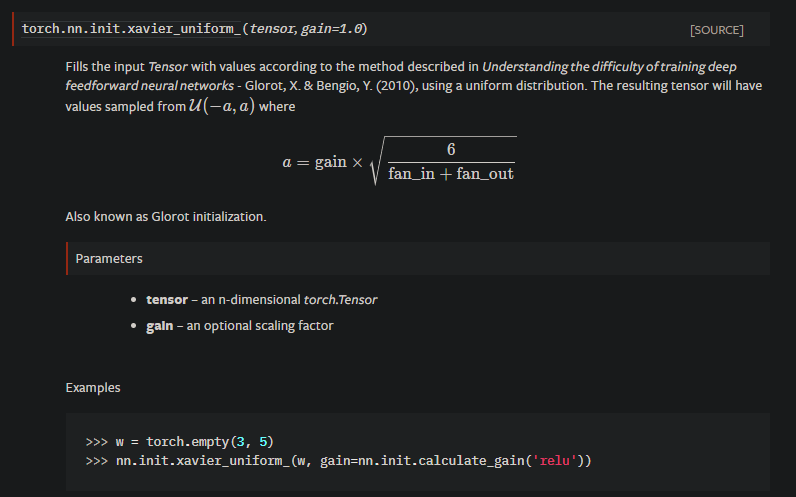
With the Uniform distributions variance being Var[W] = (1/12)* (b-a)^2 the way the weights are initialized for nn.Linear seems to fulfill Eq. 15 in [Xavier] which states that it should be n*Var[W] = 1/3
Isn’t the weight initialization thus Xavier?
Where in the paper, the target activation function was ReLU which has gain=1. Based on this, default weight init of Linear or Conv layers in PyTorch where follows Kaiming He uniform but the gain and negative slope has been defined in a way that it is a simple uniform as the way it has been explained in the thread I posted first.
One of the differences is that in Xavier you incorporate both fan_in and fan_out in the equation but Kaiming only uses one. Note that you can obtain Xavier from Kaiming by setting negative_slope=0 and fan_out=0. But it does not work as fan_out=0 does not make sense in neural networks.
In the same way that you can get Xavier from Kaiming, you can get standard uniform from Kaiming too.