I think my model’s parameters are very small. The histgrams below shows that most of the parameters are < 0.1. I am worried that this makes my model sensitive to floating point precision.
My model is a very typical autoregressive generative model with 12 decoder-only transformer layers (almost identical to GPT-2)
Is the scale of my model’s parameters acceptable?
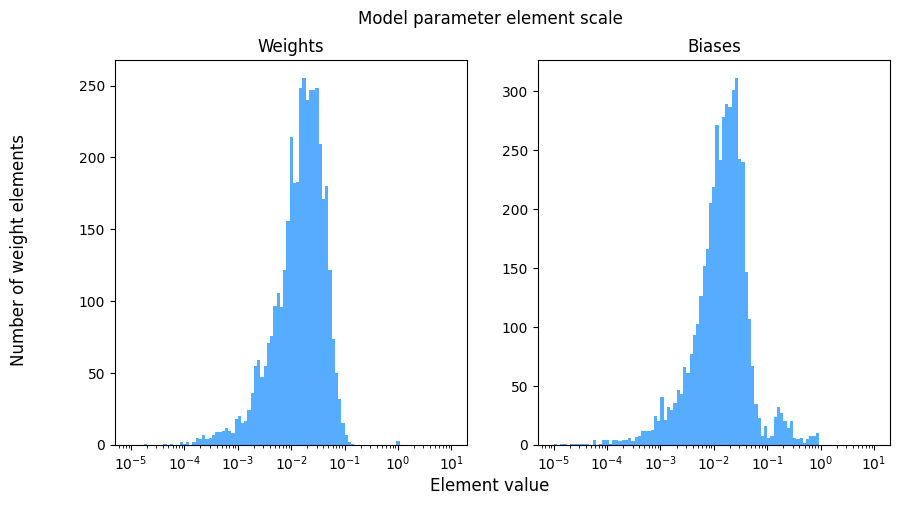
You can create these histgrams with your own model parameters with the code below.
Can anyone share your model’s parameter scale?
import numpy as np
import torch
import matplotlib.pyplot as plt
def visualize_parameter_scale(state_dict_path:str, n_shown:int=1e5)->None:
"""Visualize your model's parameter scale with histgrams.
Args:
state_dict_path (str): Path to a state dict that stores model parameters.
n_shown (int, optional): If specified, the given number of parameters are randomly sampled for plot.
The default is 100,000. If you want to plot everyhting, set this to None.
Returns:
None
"""
# Load state dict
sd = torch.load(state_dict_path, map_location="cpu")
# Collect params
weights = []
biases = []
for k, v in sd.items():
f = v.flatten().numpy()
if ".weight" in k:
weights.append(f)
elif ".bias" in k:
biases.append(f)
weights = np.hstack(weights)
biases = np.hstack(biases)
if n_shown is not None:
n_shown = int(n_shown)
weights = np.random.choice(weights, n_shown)
biases = np.random.choice(biases, n_shown)
# plot
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].hist(x=weights, bins=np.logspace(-5, 1, 100), color='dodgerblue', alpha=0.75)
axes[0].set_xscale('log')
axes[0].set_title("Weights")
axes[1].hist(x=biases, bins=np.logspace(-5, 1, 100), color='dodgerblue', alpha=0.75)
axes[1].set_xscale('log')
axes[1].set_title("Biases")
fig.supxlabel('Element value')
fig.supylabel('Number of weight elements')
fig.suptitle("Model parameter element scale")
plt.show()