As mentioned above, do you have any good optimization solutions? Our model used an input source with a size of 1 * 150 * 128 * 128 * 3. When attempting to run it, the first conv3d instantly consumed almost 1g of memory, which is unacceptable for end-to-end deployment. When I try to reduce the duration, its memory usage becomes very low again. What should I do to optimize memory usage? I have tried quantifying fp16 and int8, but they have not worked and instead have increased memory usage。
My model file,
How many channels does the first convolution generate?
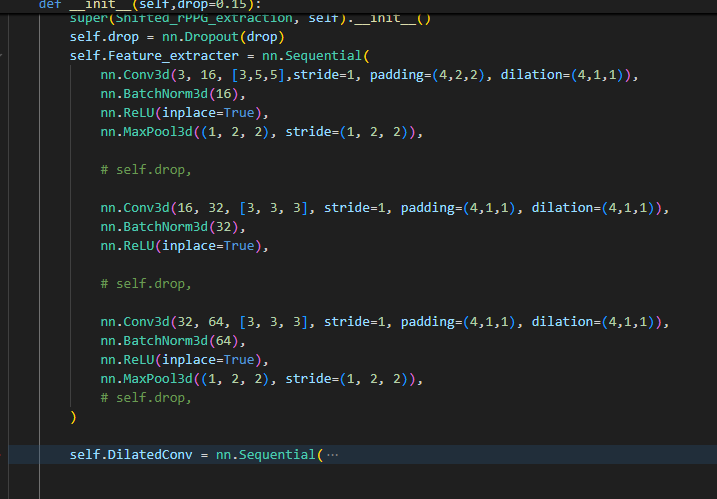
and my input was [1,3,150,128,128]
I cannot reproduce any issues and see the expected memory usage:
print("{:.2f}MB used".format(torch.cuda.memory_allocated()/ 1024**2))
# 0.00MB used
device = "cuda"
x = torch.randn(1, 3, 150, 128, 128, device=device)
conv = nn.Conv3d(3, 16, [3, 5, 5], stride=1, padding=(4, 2, 2), dilation=(4, 1, 1)).to(device)
print("{:.2f}MB used".format(torch.cuda.memory_allocated()/ 1024**2))
# 28.14MB used
out = conv(x)
print("{:.2f}MB used".format(torch.cuda.memory_allocated()/ 1024**2))
# 178.14MB used
I just tried using your method to call only one conv3d separately, and the memory usage is within an acceptable range. However, if I execute the following code, it will estimated to occupy 1g of memory. Is there any good optimization solution for this? I am trying to convert this model into onnx, which only takes up less than 500mb of memory on mobile devices, while the first layer of this model (the following code) uses 1g
Thank you for your reply
self.Feature_extracter = nn.Sequential(
nn.Conv3d(3, 16, [3,5,5],stride=1, padding=(4,2,2), dilation=(4,1,1)),
nn.BatchNorm3d(16),
nn.ReLU(inplace=True),
nn.MaxPool3d((1, 2, 2), stride=(1, 2, 2)),
# self.drop,
nn.Conv3d(16, 32, [3, 3, 3], stride=1, padding=(4,1,1), dilation=(4,1,1)),
nn.BatchNorm3d(32),
nn.ReLU(inplace=True),
# self.drop,
nn.Conv3d(32, 64, [3, 3, 3], stride=1, padding=(4,1,1), dilation=(4,1,1)),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
nn.MaxPool3d((1, 2, 2), stride=(1, 2, 2)),
# self.drop,
)
I once tried to disassemble Sequential, but it seems that the memory usage will only be released after the model has finished running. Is there a way to release it in advance?
Intermediate forward activations will be stored to compute the gradients during the backwards pass. If you don’t want to compute gradients, use torch.no_grad() to disable storing intermediates.
I followed your method and it seems to have worked, saving a little bit of memory, but it still seems to be an unacceptable usage size on mobile devices. May I ask what method can I use to obtain the memory usage situation? Such as how much memory is occupied by that parameter, etc