Hi, friends,
Now I am exploring another PyTorch Deep-Learning model upon patients’ medical-appoint booking behaviours. This time it is to predict which weekday (from Monday to Friday) a patient will book a medical appointment. The range is 0 (for Monday) to 4 (for Friday).
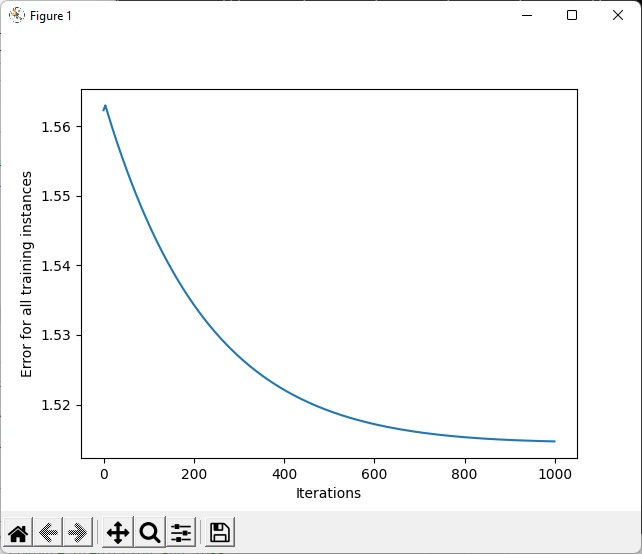
This is not a so complex user case. However, the accuracy rate of my model is still quite low: even after 1,000 epochs, the accuracy rate is only 25.3%, and the average loss is 1.608337.
However, low accuracy rate is not the whole problem. To be worse, after debugging the deep-learning model, I found that somehow the output values of the model actually converges to 4 (Friday). It is understandable that the label 4 gets the highest percentage (is this due to a “relexable Friday” many people appreciate?) among the training data (26.2%) and the testing data (25.3%, that’s why the accuracy rate is 25.3%!), but all predicted results converging to a single label is still quite abnormal.
The scenario of all-predicted-result-convert-to-a-single-label is shown in the output text below:
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
testing–>pred = tensor([[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038]])
testing–>y = tensor([0, 2, 0, 2, 2, 2, 4, 1, 4, 0])
testing–>loss = 1.7076622247695923
testing–>pred.argmax(1) = tensor([4, 4, 4, 4, 4, 4, 4, 4, 4, 4])
testing–>(pred.argmax(1) == y) = tensor([False, False, False, False, False, False, True, False, True, False])
testing–>corr = 2.0
testing–>pred = tensor([[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038]])
testing–>y = tensor([0, 4, 4, 4, 1, 1, 4, 2, 1, 4])
testing–>loss = 1.4987714290618896
testing–>pred.argmax(1) = tensor([4, 4, 4, 4, 4, 4, 4, 4, 4, 4])
testing–>(pred.argmax(1) == y) = tensor([False, True, True, True, False, False, True, False, False, True])
testing–>corr = 5.0
testing–>pred = tensor([[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038],
[-0.4787, 0.1151, 0.0034, 0.0423, 0.3038]])
testing–>y = tensor([2, 1, 2, 4, 3, 4, 0, 4, 4])
testing–>loss = 1.5375866889953613
testing–>pred.argmax(1) = tensor([4, 4, 4, 4, 4, 4, 4, 4, 4])
testing–>(pred.argmax(1) == y) = tensor([False, False, False, True, False, True, False, True, True])
testing–>corr = 4.0
Test Error:
Accuracy: 25.3%, Avg loss: 1.608337
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
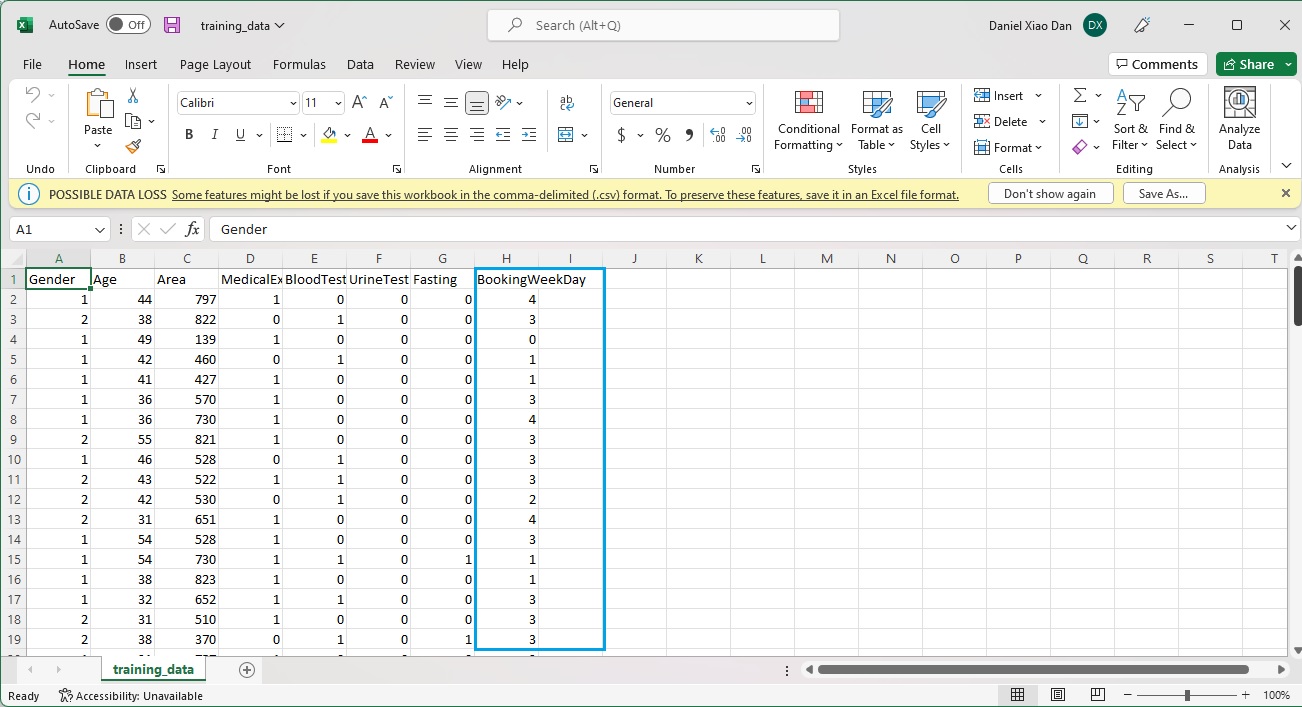
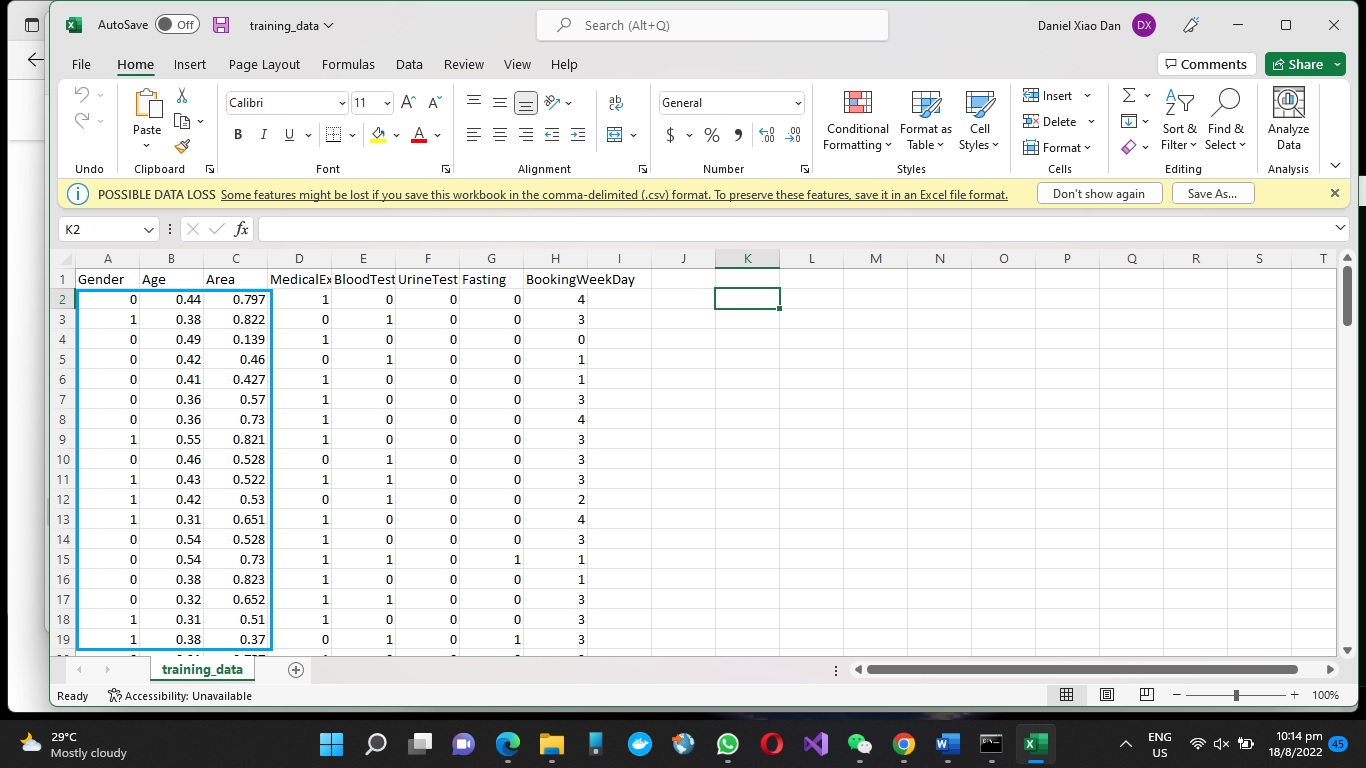
In my model, the data tensor is a vector composed of the following 7 fields:
- Gender: 1 – male, 2 – female
- Age
- Area: I take the first 3 digits of a patient’s residential postal codes and map to an integer from 0 to 999.
- Medical Examination: 1 – yes, 0 – no
- Blood Test: 1 – yes, 0 – no
- Urine Test: 1 – yes, 0 – no
- Fasting: 1 – yes, 0 – no
The labels of my model are from 0 (for Monday) to 4 (for Friday), totally 5 categories.
Totally I prepare 397 training data and 99 testing data for the deep-learning model.
My deep-learning model has followed the Fashion-MNIST learning model from the tutorials in pytorch.org official website (see the hyperlink Optimizing Model Parameters — PyTorch Tutorials 1.12.0+cu102 documentation). In the model, I also take the following parameters: the size of middle layer in the Neural Network is 512, the learning rate is 0.01 and the batch size is 10. (At the end of this post, I will attach the full set of my python source codes for your reference).
Can anybody help me to analyse and diagnose why all predicted values will converge to a single value? Is this due to the “overfitting” issue or the learning rate is still too high?
Thanks for the help. If you need more info to investigate the issue, please just let me know.
My source codes of the Pytorch deep-learning model:
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
import numpy as np
import pandas as pd
class CustomDataset(Dataset):
‘Characterizes a dataset for PyTorch’
def init(self, csv_file):
“”"
Args:
csv_file (string): Path to the csv file.
“”"
raw_data = pd.read_csv(csv_file)
raw_data = torch.tensor(raw_data.to_numpy())
x_size = list(raw_data.size())[1]
self.data_tensor = raw_data[:,:x_size-1].clone()
self.data_tensor = self.data_tensor.type(torch.float32)
self.label_tensor = raw_data[:,x_size-1:].clone()
self.label_tensor = self.label_tensor.flatten()
print(f"self.label_tensor.size() = {self.label_tensor.size()}")
def len(self):
‘Denotes the total number of samples’
return len(self.data_tensor)
def getitem(self, index):
data, label = self.data_tensor[index], self.label_tensor[index]
return data, label
training_data_csv_file = “D:\Tools\PyTorch\Medex-Deep-Learning-Model\input_data\training_data.csv”
training_data = CustomDataset(training_data_csv_file)
test_data_csv_file = “D:\Tools\PyTorch\Medex-Deep-Learning-Model\input_data\testing_data.csv”
test_data = CustomDataset(test_data_csv_file)
train_dataloader = DataLoader(training_data, batch_size=10)
test_dataloader = DataLoader(test_data, batch_size=10)
class NeuralNetwork(nn.Module):
def init(self):
super(NeuralNetwork, self).init()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(7, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 5),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
print(f’size = {size}‘);
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
print(f’pred = {pred}’);
print(f’y = {y}‘);
loss = loss_fn(pred, y)
print(f’loss = {loss}’);
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
learning_rate = 0.01
batch_size = 10
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
print(f'testing-->pred = {pred}');
print(f'testing-->y = {y}');
loss = loss_fn(pred, y).item()
print(f'testing-->loss = {loss}');
test_loss += loss
print(f'testing-->pred.argmax(1) = {pred.argmax(1)}');
print(f'testing-->(pred.argmax(1) == y) = {(pred.argmax(1) == y)}');
corr = (pred.argmax(1) == y).type(torch.float).sum().item()
print(f'testing-->corr = {corr}');
correct += corr
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)