I have a function that is used at the end of my model and I would like to backpropogate the error through this function. However when I check the gradients they are extremely small leading me to believe the gradient tracking is not working as desired.
The function itself looks as follows:
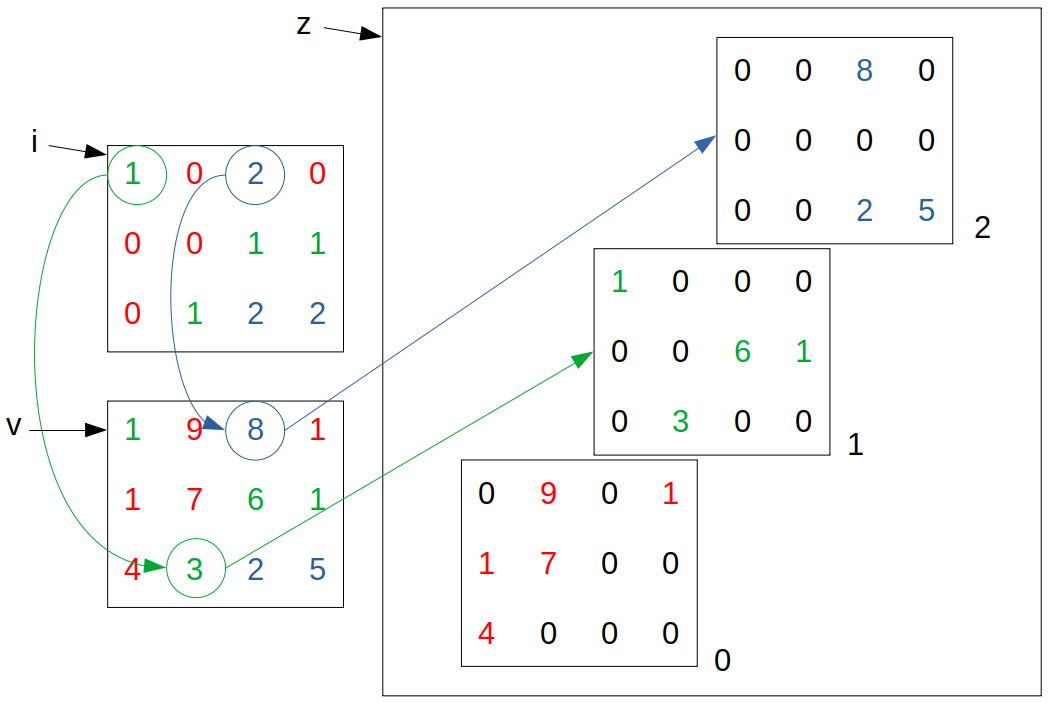
z = torch.stack([*map(i.__eq__,torch.unique(i))]).type(torch.float)*(torch.stack([v]*z.shape[0])).type(torch.float)
It’s quite a complicated function (from this original post) which uses *map and .__eq__ which are not native PyTorch functions and therefore I have a suspicion that one of these are the main issue with tracking gradients.
As the operation is quite complex, I have provided a graphical representation for visualising the operation below to help understand what the line does for given input tensors: i, v, and z. Here, the tensor i dictates which channels of tensor z that the elements of tensor v fall into.
Is there a quick and easy way to test the gradient tracking through this function?
Side note: If there is no way to quickly test whether the gradients can be tracked, maybe it is worth me posting a feature request to have an almost unit-test style functionality for checking functions are appropriate to place within networks…?
I agree it’s very fun to write one liners like that, but that does not really make the code easily readable.
One thing to check is wether or not your output does require gradients or not. In this case, I think the left side of the multiplication won’t as the __eq__ operation is not differentiable.
The right side though should be differentiable. (as long as v is a Tensor that requires gradients).
For testing if the gradients computed are the actual gradients of your function, you can use our gradcheck utility. You must run this in double precision. And it will check that gradients computed with finite difference match the ones from the autograd.
I agree that was a little cheeky of me, I’ve tried to make it a bit clearer by providing a visual representation of the code’s operation. I tried to avoid repeating what I wrote for the post linked in my question as I’m more focused on wondering why the gradient tree breaks here but I realise I made the question difficult to understand because of that
I’m going to check whether the output of the operation requires gradients now and split up the code into the two parts of the multiplication like you suggest and check them both.
Thanks for the pointer to gradcheck I’m going to see if I can get that working too, it’d be nice to seed a testfile with checks to track the gradient flow!
Ahhh that’s great, it’s so simple and clean! Thank you for having a look! Out of curiosity is there a way to allow the gradient to flow back to the indices as well? In my case these are actually something that needs learning alongside the scattered values…it’s a strange network!
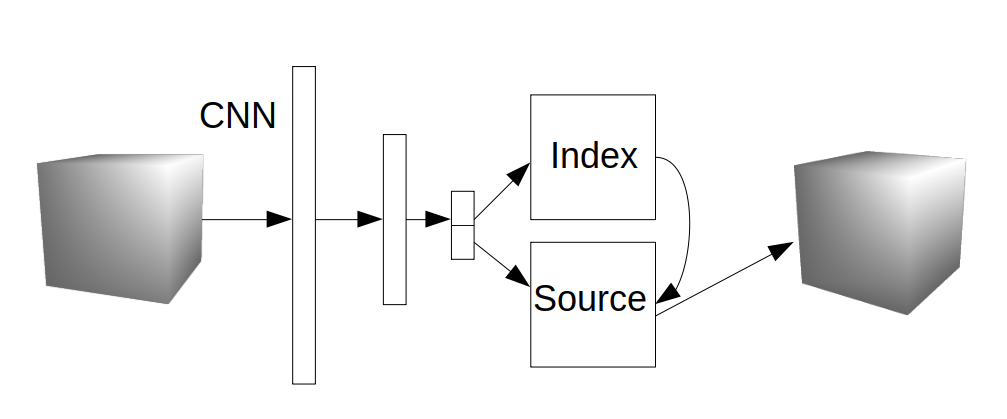
Think, something like this, where Index is i in the above visualisation, Source is v, and the output cube is z.
Here, I think because the index is something that is learned through the CNN part of the network there should be some way to allow for the gradients to flow back through the Index tensor. (See related post for this argument)
Edit: Perhaps using the out-of-place operation torch.Tensor.scatter() solves this?
The problem is that indices are integers. So gradients don’t really exist for them.
For the same reason that argmax is not differentiable.
The trick that is often used to replace indexing is to use weighted sum.
Instead of having an index in {0, 1, 2}, you have 3 values that sum to 1. And that gives you the probability of the index to be each of these values. Then you can replace indexing by weighted sum by these weights.
This works in some cases where there are not too many indices. But might not be feasible if your usecase actually require indices.
I can give that a try with my usecase and see what happens! It might not work as in actual fact I have (1,120,64,64) cube inputs/outputs but it’s worth a shot
The difficulty here is that the network is specifically designed to learn the indices as a 2D tensor before blowing up to the full cube…I’m not sure how to get around this without indexing being incurred as a result (eventually) because the step from learned parameters to the index tensor is an analytical one rather than a learned one if that makes sense…
Perhaps there is a way of combining scatter with grid_sample like in this post? (Although I see in the docs that it only supports spatial indexing, so 2D idexing)
As the creation of the learned index tensor is a multi-stage process (involving the learning of a float tensor which is then transformed into a tensor of intigers), do you think there is any way to bypass the intiger-index tensor for calculating the gradient from inside the gradient tree? Perhaps a subunit of somekind?
Something like the following, where the green arrows show the gradient flow and the black arrows show the forward pass…
Well I don’t know what this green arrow would compute.
But if you have a formula for it, you can create a new autograd Function as described here to define your own backward for a non-differentiable forward.
Hi @albanD, I’ve been thinking about this reply a lot and I think I may have a way to do it but I thought I’d run it by you as initial tests have shown that the gradient tree is still broken somewhere.
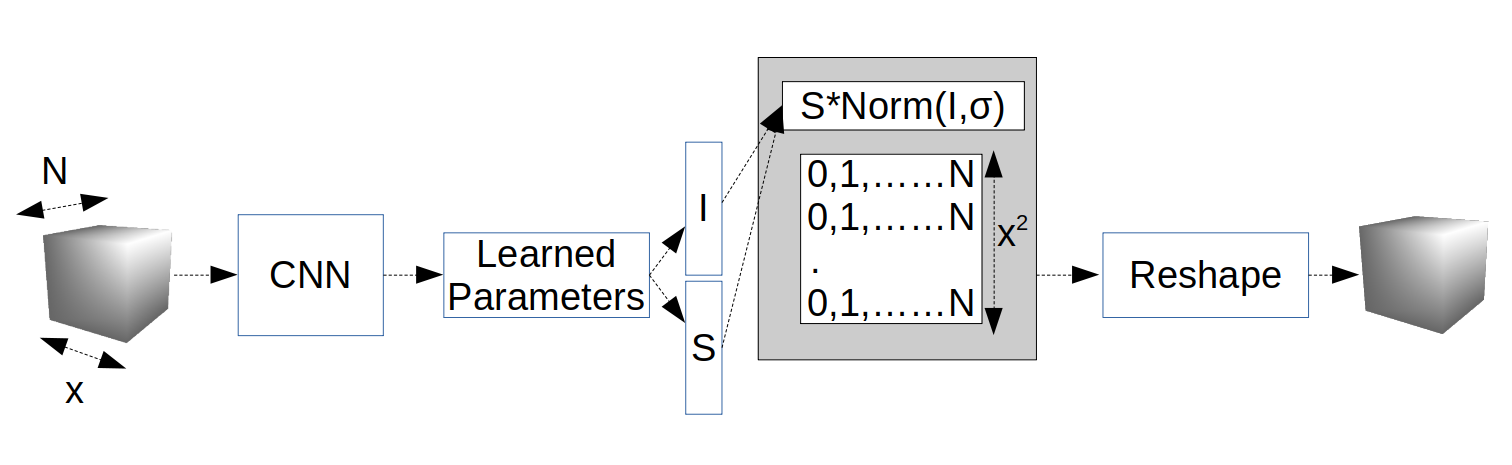
Where I and S are flattened replacements of the 2D arrays as seen in the previous post.
Now instead of indexing, the indices from I are used at the mean values of a series of normal distributions evaluated over the 2D array with dimensions N by x^2, and using some predefined σ.
Then a simple reshaping turns this 2D array back into the original cube shape.
As there is no indexing here, I shouldn’t think it would break the gradient tree…but is there something very obvious I’ve missed that you think would cause this method to fail?
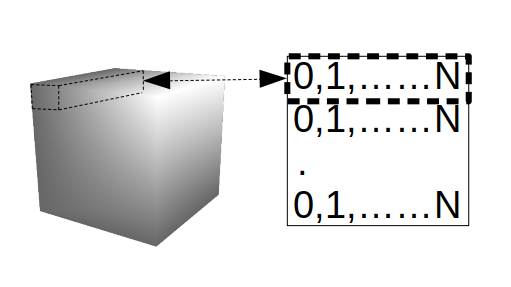
Note: One can think of the 2D array (with dimensions N by x^2) as a flattened version of a cube where each row represents the channel indices of a cube spaxel C_ij. Pictorially this looks as follows:
…where the maximum value of C_ij is normally distributed about I_ij with size S_ij.
Does that mean that you will need to backward through the operation of “evaluating a series of normal distributions” ? Is that differentiable wrt the mean?
I’ve done some thinking and I think it should be differentiable wrt the mean…
My normal is simply the following:
def normal(self,mu,std,auxiliary,amplitude):
mu = mu.view(-1)
amplitude = amplitude.view(-1)
a = 1/(std*torch.sqrt(2*torch.tensor(pi)))
b = torch.exp(-0.5*(((auxiliary-mu[:,None])/std)**2))
return amplitude[:,None]*(a*b)
Where auxiliary just refers to the 2D array with dimensions N by x^2 above.
Perhaps I should be using an inbuilt Pytorch normal distribution mechanism, or my handling of evaluating many normal distributions in one go (like in the code above) creates problems I can’t see… but as far as I can tell the differential of a normal distribution wrt the mean is possible. So I’m not sure what I’m doing wrong.
In retrospect I now understand that the differential of a series of evaluated normal distributions with means, given as I in the post above, will simply return a zero so this is not a good way of tackling the problem.
That being said, would it not be possible to use an extension of autograd to simply backprop dL/dI = tensor-of-ones for the non-differentiable forward (in this case at the indexing step), or does that still prevent backprop functioning correctly for learning?