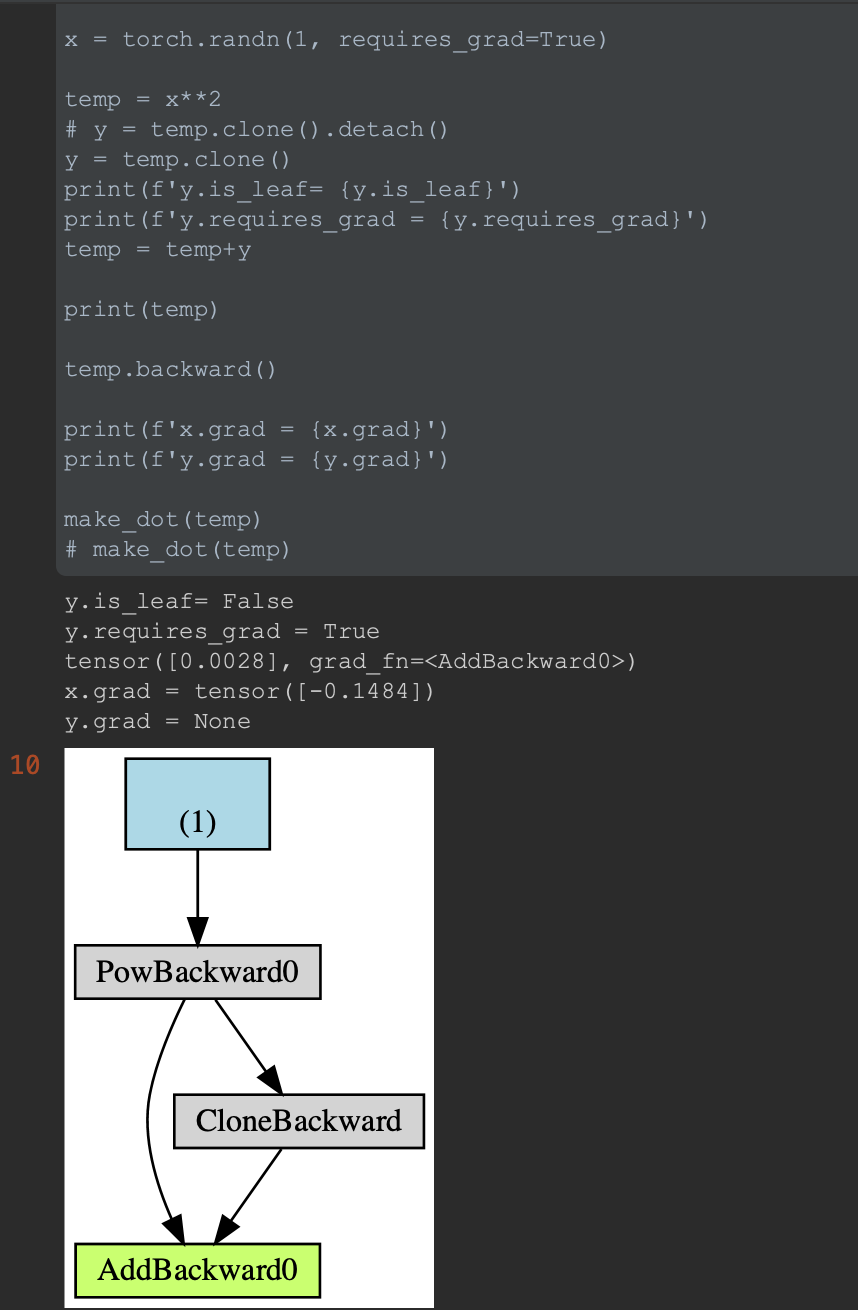
I guess because we are creating an actual tensor (i.e. we are using a clone operation) I expected the new vector to be a leaf (or something “new”). Thus it seemed odd to me that it would be considered the identity function, because those two operation don’t seem the same to me…but I guess clone is just the identity? Whats the point of clone then?
Clone is an identity with new memory. The same way you could use new = t.view_as(t) would be an identity with the exact same memory.
The main use of clone is to be able to do inplace operations on the result without impacting the original Tensor.
Note that in pytorch, all functions will be differentiated and give you gradients. The only exception is .detach() that is defined as setting all gradients to 0 and the ops inside a torch.no_grad() block that are not tracked.
Yes. If you want to have a new Tensor that has no gradient history, you should use detach().
Note that the result of detach() uses the same memory space as the original Tensor. So if you plan on modifying it inplace, you want to do .clone().detach().
I plan to create a completely separate computation graph (and don’t want the call of backwards to interfere with each other). For that I am running requires_flag=True immediately after .detach(). Is that the right thing to do?
However, the original wt is going to collect gradients with respect to the original graph. So if I call .detach() wouldn’t it collect the gradients for both graphs in the same tensor? That’s definitively not what I want. I want separate gradients (or at least that’s my rationale for calling .clone() first and then .detach()). What are your thoughts master albanD?
In pytorch, it is different to have different Tensor and have different memory.
When you do b = a.detach(), a and b are two completely different Tensors that look at the same memory.
Just like b = a.view(-1) are two different Tensors that look at the same memory.
The inplace version (that would modify the Tensor inplace) is a.detach_() or b = a.detach_(). If you do this, then a and b actually point to the exact same python object (check that id(a) == id(b)) and same Tensor.
I guess to answer my own question, I do not need to call clone it seems. The new tensor tracks its own memory space for its gradients automagically (without interference, so it doesn’t collect the same gradients for both graphs in the same place):
import torch
a = torch.tensor([2.0], requires_grad=True)
b = a.detach()
b.requires_grad = True
la = (5.0 - a)**2
la.backward()
print(f'a.grad = {a.grad}')
lb = (6.0 - b)**2
lb.backward()
print(f'b.grad = {b.grad}')
result:
a.grad = tensor([-6.])
b.grad = tensor([-8.])
of course you guys would have thought of a good implementation of this! Not surprised!
I can’t think of one except making 2 variables pointing to different memories and then doing inplace ops separately for each one or something like that…which seems dangerous…
There are a few.
For example if you want to save the current state of the weights of your net, you want to clone because the optimizer update works inplace and so your save will change with your network if you don’t clone.
My earlier post checked that two tensors really are detached by comparing gradients. Is there an internal flag to check something like this? A nicer way to check that b is detached?
that’s not enough because I am setting the requires gradients true myself later. See sample script (where in it I check they are actually detached and form a separate graph by computing gradients I manually know how to check, but thats harder to check in a complicated net however):
import torch
a = torch.tensor([2.0], requires_grad=True)
b = a.detach()
b.requires_grad = True
la = (5.0 - a)**2
la.backward()
print(f'a.grad = {a.grad}')
lb = (6.0 - b)**2
lb.backward()
print(f'b.grad = {b.grad}')