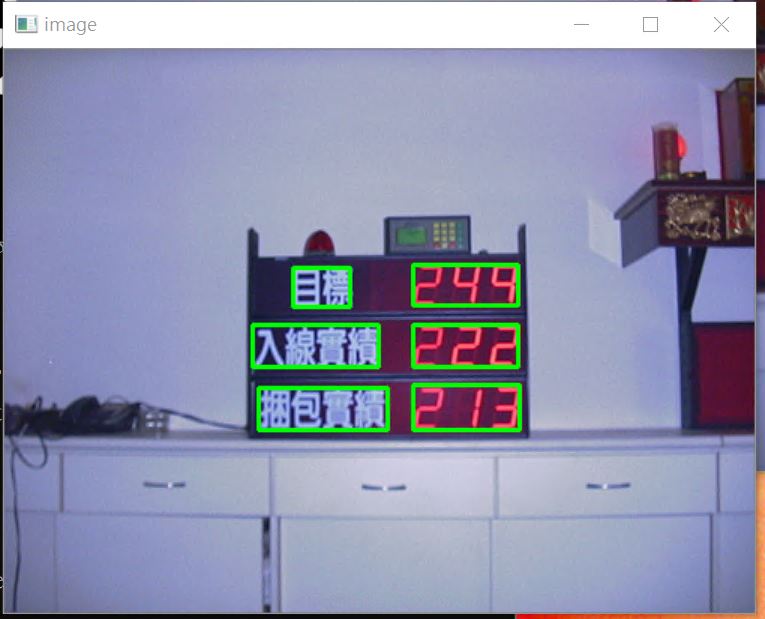
I tested a model with different results in the case of CUDA and CPU.
The condition of the CPU can produce results normally.
But in the case of CUDA, I have to convert the output to the CPU before I can execute it, but the result of the execution is incorrect.
Haha!
Actually, I don’t know why I want to use it. It’s just from the Internet.
Because I am not using it for training, I just use it to predict, so the result of the implementation is no problem.
The part with detach() is that the CPU can execute normally without problems.
If you just use this for evaluation, you should use the NoGradGuard (not sure about the exact name, but something along those lines) to completely disable the autograd (that will make you code faster and use less memory) !
I guess there is something wrong in the way you send the model on the gpu. Are you sure that the weights / inputs to the network are properly sent to the gpu?
As you can see, I switched the CUDA to the CPU in the same program, so all the method and process is the same, I don’t know why the result is different?
You should be able to print to stdout the values of the different tensors (both cpu and gpu), can you print the inputs, weights and outputs to see where the difference appears?
As I said above, you should inspect when the discrepancy appears. It is when you load the weights? Or on the inputs or when you apply the forward pass?
Ok, I will try it out.
But I want to put my model and code on github, if you can, please try it out (please pay attention to the operation instructions, choose 1 for CUDA, 2 for CPU).
You should know it, it seems very strange.
Because the model is not small, please note that if you use the GPU, the GPU RAM should not be too small, otherwise it will be destroyed.
Hello, the classifier trained by Resnet50 works well in python. The same test data has poor classification accuracy in C++(libtorch) calls. I don’t know why. Have you met it? thank you!
Did you make sure to use the same preprocessing etc.?
I would recommend to check the inputs first and get the same values in the Python API and libtorch and then try to narrow down the discrepancy.
You are not the first one to have such problem. I have a similar one here and there is another unanswered one here.
I suggest you try to locate the source of divergence by yourself first, it makes it easier to help you. I had a Python code, not C++, but I’ll share it here so you get the idea on how to locate the problem.
Save off the intermediate variables on CPU and GPU inference: torch.save(variable, "/path/to/varfile")