The model is just a resnet50, finetuned on a 1.6m images dataset.
The first 10k steps just took about 106m, which the 10k steps from 30k to 40k took about 171m.
Before around 15k steps, the gpu util is quite stable and nearly reach 100%. Afterwards, the gpu util begins to jitter rapidly and seems periodically from 0~100%, but pcie bandwidth util is quite low(occasionally reach 60%) and the loading subprocesses seem to work fine: the cpu utilization is low and the disk reading speed is low (checked with iotop) which I guess is a sign that every loading subprocess has already loaded sufficient data. The gpu temperature is not high either(69C top) and gpu on the highest performace level.
Why does this happen? Is there any solutions?
ps. the image files reside in a ssd. the batch size is 64. The nivida-smi daemon mode is on. Once I stopped after the first epoch, and then loaded the trained model and resumed training, the speeds of the two epoch were quite same, as opposed to training continuously.
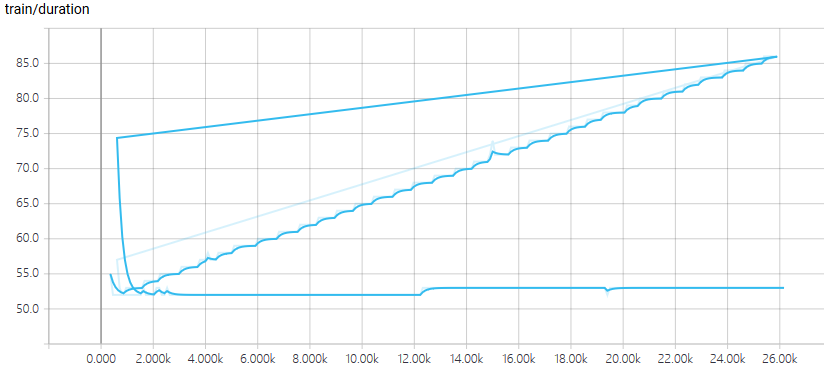
Sorry about the step overlap. The linearly growing part corresponds to code without torch.cuda.empty_cache(), and the lower stable part corresponds to code with this magic command.
And as I stated before, even without this command, the gpu memory utilization is quite stable during the whole training process. So I’m quite confused too.
I am using pytorch version 1.1.0 and facing the same issue where the training time per step increases within the epoch. I tried removing all the lists/other data objects that could result in storing variables from previous iterations but that did not help. Any suggestions? Also, I am using multiple GPUs to train my model and using nn.DataParallel package