@SimonW
0.3.0.post4
And here’s a duration plot every 100 batches.
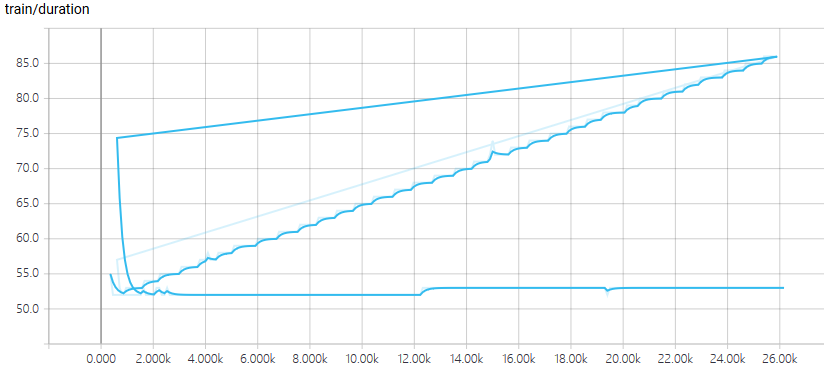
Sorry about the step overlap. The linearly growing part corresponds to code without
torch.cuda.empty_cache(), and the lower stable part corresponds to code with this magic command.
And as I stated before, even without this command, the gpu memory utilization is quite stable during the whole training process. So I’m quite confused too.