TLDR:
A simple (single hidden-layer) feed-forward Pytorch model trained to predict the function y = sin(X1) + sin(X2) + ... sin(X10) substantially underperforms an identical model built/trained with Keras. Why is this so and what can be done to mitigate the difference in performance?
In training a regression model, I noticed that PyTorch drastically underperforms an identical model built with Keras.
This phenomenon has been observed and reported previously:
-
The same model produces worse results on pytorch than on tensorflow
-
CNN model in pytorch giving 30% less accuracy to Tensoflowflow model:
-
PyTorch comparable but worse than keras on a simple feed forward network
-
Why Keras behave better than Pytorch under the same network configuration?
The following explanations and suggestions have been made previously as well:
-
Change
retain_graph=Truetocreate_graph=Truein computing the 2nd derivative withautograd.grad: 1 -
Check if keras is using a regularizer, constraint, bias, or loss function in a different way from pytorch: 1,2
-
Ensure you are computing the validation loss in the same way: 1
-
Training the pytorch model for longer epochs: 1
-
Trying several random seeds: 1
-
Ensure that
model.eval()is called in validation step when training pytorch model: 1 -
The main issue is with the Adam optimizer, not the initialization: 1
To understand this issue, I trained a simple two-layer neural network (much simpler than my original model) in Keras and PyTorch, using the same hyperparameters and initialization routines, and following all the recommendations listed above. However, the PyTorch model results in a mean squared error (MSE) that is 400% higher than the MSE of the Keras model.
Here is my code:
1. Generate a reproducible dataset
def get_data():
np.random.seed(0)
Xtrain = np.random.normal(0, 1, size=(7000,10))
Xval = np.random.normal(0, 1, size=(700,10))
ytrain = np.sum(np.sin(Xtrain), axis=-1)
yval = np.sum(np.sin(Xval), axis=-1)
scaler = MinMaxScaler()
ytrain = scaler.fit_transform(ytrain.reshape(-1,1)).reshape(-1)
yval = scaler.transform(yval.reshape(-1,1)).reshape(-1)
return Xtrain, Xval, ytrain, yval
class XYData(Dataset):
def __init__(self, X, y):
super(XYData, self).__init__()
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.float32)
self.len = len(y)
def __getitem__(self, index):
return (self.X[index], self.y[index])
def __len__(self):
return self.len
# Data, dataset, and dataloader
Xtrain, Xval, ytrain, yval = get_data()
traindata = XYData(Xtrain, ytrain)
valdata = XYData(Xval, yval)
trainloader = DataLoader(dataset=traindata, shuffle=True, batch_size=32, drop_last=False)
valloader = DataLoader(dataset=valdata, shuffle=True, batch_size=32, drop_last=False)
2. Build Keras and PyTorch models with identical hyperparameters and initialization methods
class TorchLinearModel(nn.Module):
def __init__(self, input_dim=10, random_seed=0):
super(TorchLinearModel, self).__init__()
_ = torch.manual_seed(random_seed)
self.hidden_layer = nn.Linear(input_dim,100)
self.initialize_layer(self.hidden_layer)
self.output_layer = nn.Linear(100, 1)
self.initialize_layer(self.output_layer)
def initialize_layer(self, layer):
_ = torch.nn.init.xavier_normal_(layer.weight)
#_ = torch.nn.init.xavier_uniform_(layer.weight)
_ = torch.nn.init.constant(layer.bias,0)
def forward(self, x):
x = self.hidden_layer(x)
x = self.output_layer(x)
return x
def mean_squared_error(ytrue, ypred):
return torch.mean(((ytrue - ypred) ** 2))
def build_torch_model():
torch_model = TorchLinearModel()
optimizer = optim.Adam(torch_model.parameters(),
betas=(0.9,0.9999),
eps=1e-7,
lr=1e-3,
weight_decay=0)
return torch_model, optimizer
def build_keras_model():
x = layers.Input(shape=10)
z = layers.Dense(units=100, activation=None, use_bias=True, kernel_regularizer=None,
bias_regularizer=None)(x)
y = layers.Dense(units=1, activation=None, use_bias=True, kernel_regularizer=None,
bias_regularizer=None)(z)
keras_model = Model(x, y, name='linear')
optimizer = Adam(learning_rate=1e-3, beta_1=0.9, beta_2=0.9999, epsilon=1e-7,
amsgrad=False)
keras_model.compile(optimizer=optimizer, loss='mean_squared_error')
return keras_model
# Instantiate models
torch_model, optimizer = build_torch_model()
keras_model = build_keras_model()
3. Train PyTorch model for 100 epochs:
torch_trainlosses, torch_vallosses = [], []
for epoch in range(100):
# Training
losses = []
_ = torch_model.train()
for i, (x,y) in enumerate(trainloader):
optimizer.zero_grad()
ypred = torch_model(x)
loss = mean_squared_error(y, ypred)
_ = loss.backward()
_ = optimizer.step()
losses.append(loss.item())
torch_trainlosses.append(np.mean(losses))
# Validation
losses = []
_ = torch_model.eval()
with torch.no_grad():
for i, (x, y) in enumerate(valloader):
ypred = torch_model(x)
loss = mean_squared_error(y, ypred)
losses.append(loss.item())
torch_vallosses.append(np.mean(losses))
print(f"epoch={epoch+1}, train_loss={torch_trainlosses[-1]:.4f}, val_loss={torch_vallosses[-1]:.4f}")
4. Train Keras model for 100 epochs:
history = keras_model.fit(Xtrain, ytrain, sample_weight=None, batch_size=32, epochs=100,
validation_data=(Xval, yval))
5. Loss in training history
plt.plot(torch_trainlosses, color='blue', label='PyTorch Train')
plt.plot(torch_vallosses, color='blue', linestyle='--', label='PyTorch Val')
plt.plot(history.history['loss'], color='brown', label='Keras Train')
plt.plot(history.history['val_loss'], color='brown', linestyle='--', label='Keras Val')
plt.legend()
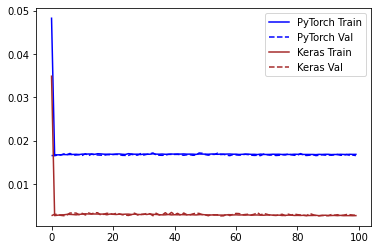
Keras records a much lower error in the training. Since this may be due to a difference in how Keras computes the loss, I calculated the prediction error on the validation set with sklearn.metrics.mean_squared_error
6. Validation error after training
ypred_keras = keras_model.predict(Xval).reshape(-1)
ypred_torch = torch_model(torch.tensor(Xval, dtype=torch.float32))
ypred_torch = ypred_torch.detach().numpy().reshape(-1)
mse_keras = metrics.mean_squared_error(yval, ypred_keras)
mse_torch = metrics.mean_squared_error(yval, ypred_torch)
print('Percent error difference:', (mse_torch / mse_keras - 1) * 100) # 438%
r_keras = pearsonr(yval, ypred_keras)[0] # 0.911
r_pytorch = pearsonr(yval, ypred_torch)[0] # 0.577
print("r_keras:", r_keras)
print("r_pytorch:", r_pytorch)
plt.scatter(ypred_keras, yval); plt.title('Keras'); plt.show(); plt.close()
plt.scatter(ypred_torch, yval); plt.title('Pytorch'); plt.show(); plt.close()
Percent error difference: 479.1312469426776
r_keras: 0.9115184443702814
r_pytorch: 0.21728812737220082
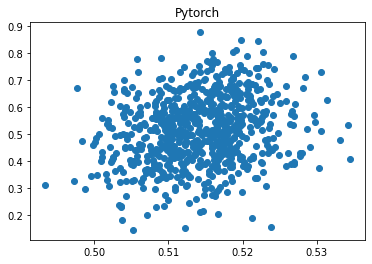
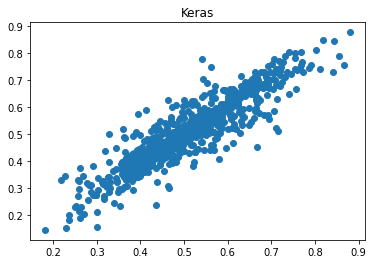
The correlation of predicted values with ground truth is 0.912 for Keras but 0.217 for Pytorch, and the error for Pytorch is 479% higher!
7. Other trials
I also tried:
- Lowering the learning rate for Pytorch (lr=1e-4), R increases from 0.217 to 0.576, but it’s still much worse than Keras (r=0.912).
- Increasing the learning rate for Pytorch (lr=1e-2), R is worse at 0.095
- Training numerous times with different random seeds. The performance is roughly the same, regardless.
- Trained for longer than 100 epochs. No improvement was observed!
- Used
torch.nn.init.xavier_uniform_instead oftorch.nn.init.xavier_normal_in the initialization of the weights. R improves from 0.217 to 0.639, but it’s still worse than Keras (0.912).
What can be done to ensure that the PyTorch model converges to a reasonable error comparable with the Keras model?