I ported a simple model (using dilated convolutions) from TensorFlow (written in Keras) to pytorch (last stable version) and the convergence is very different on pytorch, leading to results that are good but not even close of the results I got with TensorFlow. So I wonder if there are differences on optimizers in Pytorch, what I already checked is:
Same parameters for optimizer (Adam)
Same loss function
Same initialization
Same learning rate
Same architecture
Same amount of parameters
Same data augmentation / batch size
So I wonder, what else should I check ? It seems that everything was covered already. Any ideas ?
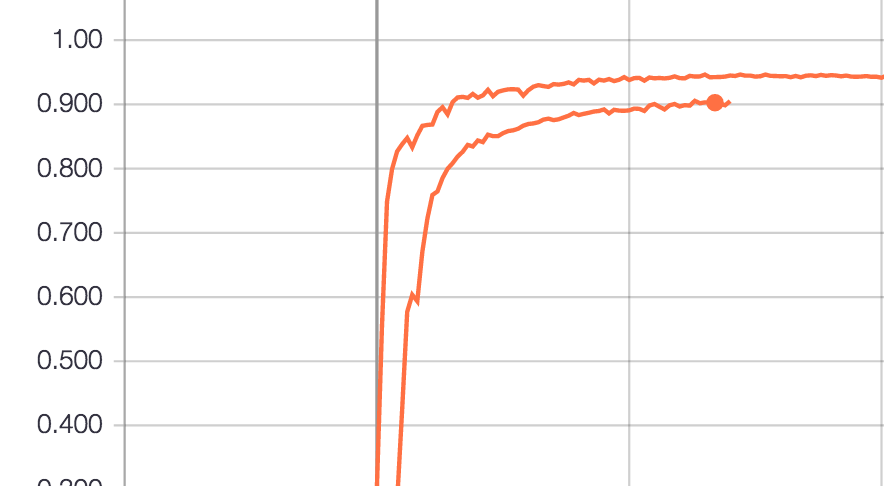
Example of convergence of the loss (unfortunately the two series are the same color, but pytorch is the one below), for this loss, higher is better:
Thanks for the answer Rodrigo ! I’m not using any constraint or regularizer and biases are also the same. I’ll try to double check everything again, but this is really weird.
Sometimes subtle differences in the definitions can make comparisons difficult, e.g. when a mean is taken in the loss function when your comparison uses a sum, you would need to compensate for that.
Also there are quite a few parameters to the optimizer that have differing defaults between implementations.
I’d probably try to start both with the same weights and see where it differs.
I initialized the model in Pytorch with the same weights of a model trained on Keras (using TensorFlow backend) and suprisingly, the results of this new model with the same weights yield the SAME results from Keras model;
However, if I train this same model on Pytorch (even using the same initialization weights), Pytorch always yields suboptimal results, like the one saw on the image above;
My opinion is that something is really weird with the Adam optimizer in Pytorch, yielding poor results when compared to Keras/TensorFlow. So my question is: how were these optimizers tested ? It is consistently yielding poor results to me. Does anyone saw that before ? Is there any workaround for that ?
Did you check the initialization and the loss, too?
I think keras uses Xavier Glorot’s method by default for some layers.
You probably could extend your comparison to the gradient and possible regularizer and then look at the optimizer step itself.
The good news is that you can probably just “bisect” the backward pass if you find that the gradients differ.
Best regards
Thomas
(who is also trying to stare down a model where he cannot make sense of the apparent training deficiency)
Thanks @tom, actually I used the same initial weights (not only the same initialization method) to train it, so it really seems to be something fundamentally wrong with the Adam optimizer itself (I also checked the loss multiple times). I think that I’ll wait for Pytorch to stabilize because I don’t have so much time to invest in debugging it, unfortunately. Dissecting every aspect of the model takes a lot of time. Good luck with your model by the way !!
This is peculiar, but thanks for testing this thoroughly. I’ve had a quick look at PyTorch Adam (seems fine) vs. TensorFlow Adam (complex, but also seems fine) vs. Keras Adam (also seems fine), and can’t spot any issues, but perhaps someone more observant will.
at first glance. it looks like tensor flow is using a slightly different version of episilon definition in their Adam . They are using the the “epsilon hat” version
they replace these three lines of algorithm:
m t ←mt/(1−β1t)(Computebias-correctedfirstmomentestimate)
v t ← vt /(1 − β2t ) (Compute bias-corrected second raw moment estimate) √
θt ←θt−1 −α·m t/( v t +ε)(Updateparameters)
with these two lines:
αt =α· 1−β2t/(1−β1t)
θt ←θt−1 −αt ·mt/(√vt +εˆ).
and just took a glance at keras and seems they are too
EDIT: Scratch that. We are using the same here as well. We use the bottom two lines as well
Tensorflow Adam – “Momentum decay (beta1) is also applied to the entire momentum
accumulator. This means that the sparse behavior is equivalent to the dense
behavior (in contrast to some momentum implementations which ignore momentum
unless a variable slice was actually used).”
Yeah this will cause performance differences.
But it’s not that pytorch is using a weird Adam optimizer in contrary it’s looks like pytorch just has the plain vanilla version. You guys see the same thing?
Note that the efficiency of algorithm 1 can, at the expense of clarity, be improved upon by changing the order of computation, e.g. by replacing the last three lines in the loop with the following lines…
So I’m surprised that it should make a noticeable difference, but maybe that is the case. @christianperone would you mind trying the altered version of Adam on your problem? Fingers crossed this might be the solution.
The bit about sparse updates with TensorFlow Adam I would assume don’t matter in this case. I don’t know how PyTorch deals with sparse modules wrt gradient updates, but what TF claims to do sounds like the correct approach.
It was this part that made me think it could lead to noticeable difference–
Tensorflow Adam – “ The sparse implementation of this algorithm (used when the gradient is an
IndexedSlices object, typically because of `tf.gather` or an embedding
lookup in the forward pass) does apply momentum to variable slices even if
they were not used in the forward pass (meaning they have a gradient equal to zero. Momentum decay (beta1) is also applied to the entire momentum
accumulator. This means that the sparse behavior is equivalent to the dense
behavior (in contrast to some momentum implementations which ignore momentum
unless a variable slice was actually used).”
As I see a lot of training embedding models in pytorch and would be comparing to tensorflow I bet a lot of these performance differences stem from that as it auto applies the momentum decay and we would have default not too.
Anyways I have always been able to get just as good or better than tensorflow performance but I usually use custom stuff most the time but the underlying framework has shown no insuffiency in performance for me and usually find quite the opposite
I’ll test it. If someone has the code change in hands that would help a lot, otherwise I’ll have to come back to this in near future due to my time constraints. Thanks for the help !
I also experienced suboptimal behaviour with Adam compared to SGD in PyTorch. Similar code in Tensorflow performed the other way around, i.e. optimizing with Adam was much easier. I have also used an Embedding layer.