Ubuntu 16.04
PyTorch v1.1
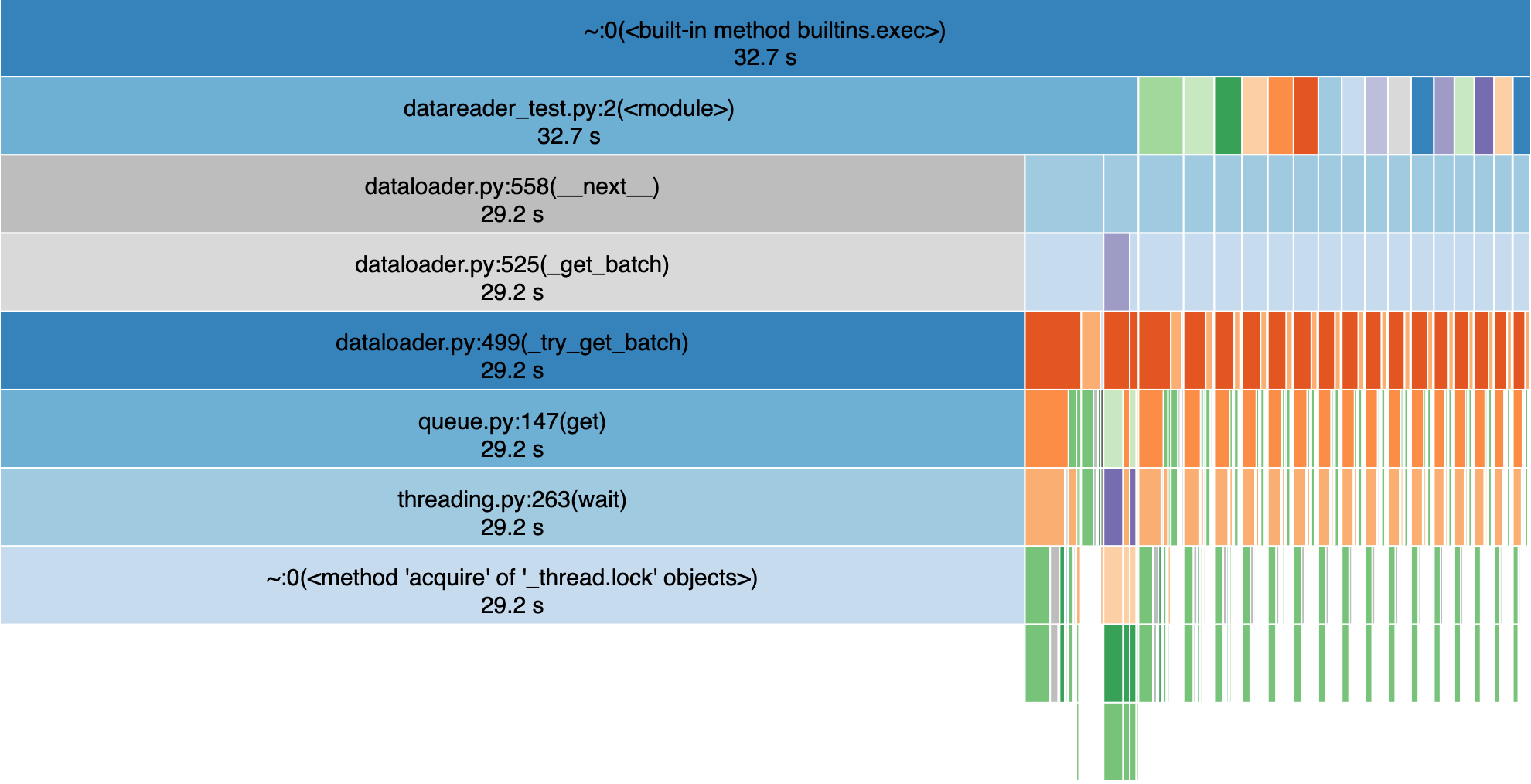
I use PyTorch’s DataLoader to read in Batches in parallel. The data is in the zarr format, multithreaded reading should be supported. To profile the data loading process, I used cProfile on a script that just loads one epoch in a for loop without doing anything else:
train_loader = torch.utils.data.DataLoader(
sampler,
batch_size=64,
shuffle=True,
num_workers=4,
pin_memory=True,
drop_last=True,
worker_init_fn=worker_init_fn,
collate_fn=BucketCollator(sampler, n_rep_years)
)
for i, batch in enumerate(train_loader):
pass
Even if the DataLoader can only use 4 CPUs, all 40 CPUs of the machine are used, but this is not the issue. The DataLoader spends most of the time on ~:0(<method 'acquire' of '_thread.lock' objects>) (see profile view 1). What does this mean? Are the processes waiting until the dataset is unlocked, even if multithread reading should work? Or is this just the time the DataLoader waits until the data is read and it is limited by the data reading speed? If this is the case, why would then all 40 CPUs run at 100%?
I appreciate any help to get a better understanding of what is going on under the hood.
EDIT: It seems _thread.lock.acquire indicates that the main process is waiting for IO. I still wonder why all 40 CPUs run on 100% when they are actually waiting for IO…
profile view 1
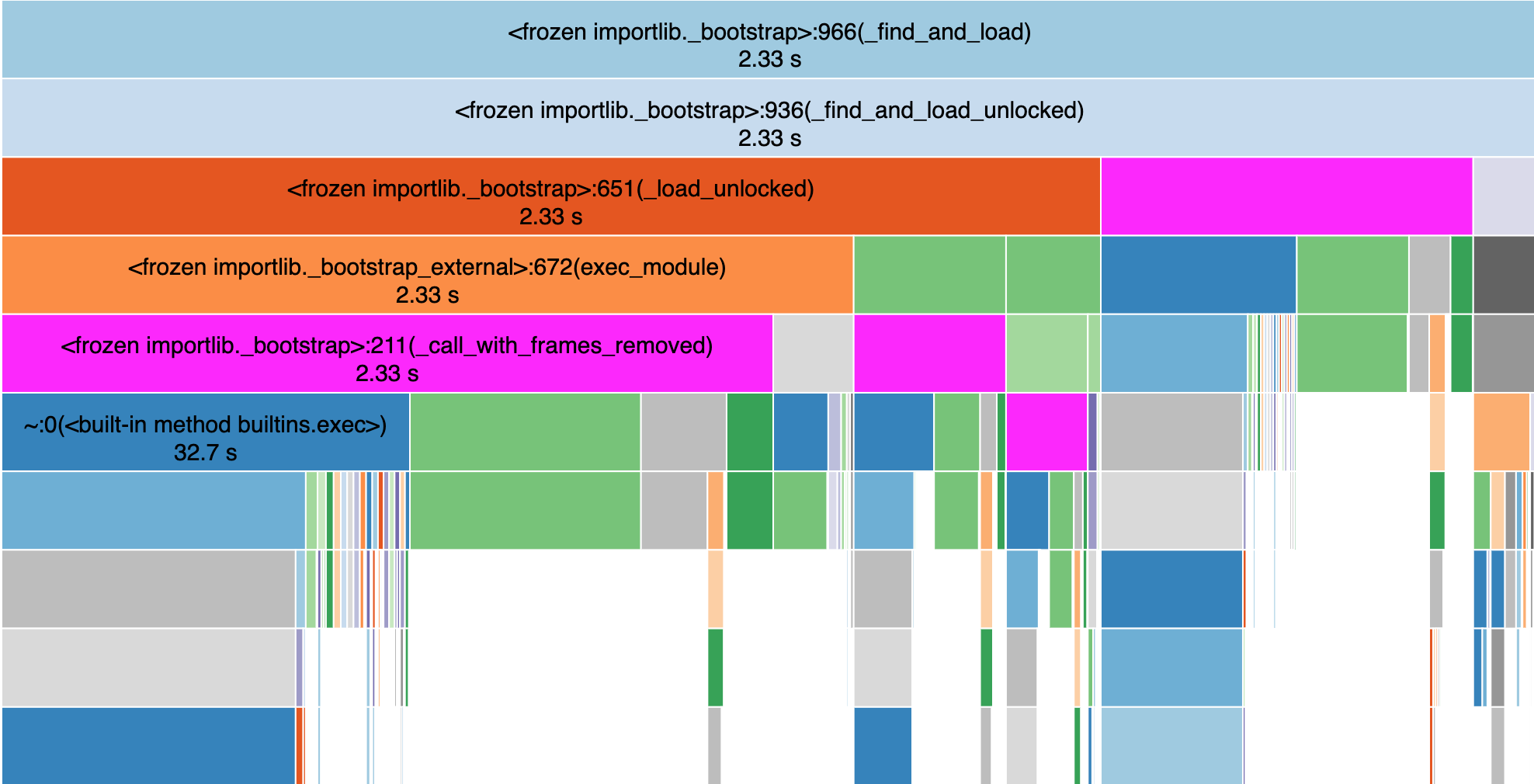
profile view 2
ncalls tottime percall cumtime percall filename:lineno(function)
891 29.21 0.03278 29.21 0.03278 ~:0(<method 'acquire' of '_thread.lock' objects>)
117/116 0.22 0.001896 0.2244 0.001935 ~:0(<built-in method _imp.create_dynamic>)
1095 0.136 0.0001242 0.136 0.0001242 ~:0(<built-in method marshal.loads>)
10378 0.1329 1.281e-05 0.9031 8.702e-05 core.py:1552(_chunk_getitem)
11208 0.113 1.008e-05 0.1131 1.009e-05 ~:0(<built-in method io.open>)
20560 0.1107 5.382e-06 0.1107 5.382e-06 ~:0(<built-in method posix.stat>)
60 0.09576 0.001596 0.2934 0.004891 afm.py:201(_parse_char_metrics)
10424 0.08875 8.514e-06 0.3511 3.368e-05 storage.py:721(__getitem__)
107531 0.07747 7.204e-07 0.1234 1.147e-06 afm.py:61(_to_float)
31124 0.06565 2.109e-06 0.06565 2.109e-06 core.py:359(<genexpr>)
3035/2950 0.06219 2.108e-05 0.2543 8.622e-05 ~:0(<built-in method builtins.__build_class__>)
10524 0.05762 5.475e-06 0.05762 5.475e-06 ~:0(<method 'read' of '_io.BufferedReader' objects>)
46 0.05739 0.001248 0.1434 0.003118 afm.py:253(_parse_kern_pairs)
314835/314125 0.05286 1.683e-07 0.06002 1.911e-07 ~:0(<built-in method builtins.isinstance>)
10392 0.05215 5.019e-06 0.08863 8.529e-06 indexing.py:293(__iter__)
1542/1 0.04539 0.04539 32.7 32.7 ~:0(<built-in method builtins.exec>)
10372 0.03969 3.827e-06 0.1322 1.274e-05 core.py:1731(_decode_chunk)
12348 0.03371 2.73e-06 0.05517 4.468e-06 posixpath.py:75(join)
71255 0.03229 4.531e-07 0.05519 7.745e-07 afm.py:232(<genexpr>)
96237 0.031 3.221e-07 0.031 3.221e-07 ~:0(<method 'split' of 'str' objects>)
11 0.03053 0.002776 0.03053 0.002776 ~:0(<built-in method torch._C._cuda_isDriverSufficient>)
1329/5 0.02997 0.005995 2.329 0.4658 <frozen importlib._bootstrap>:966(_find_and_load)
2461 0.02855 1.16e-05 0.1294 5.26e-05 <frozen importlib._bootstrap_external>:1233(find_spec)
33889 0.02833 8.36e-07 0.02833 8.36e-07 ~:0(<built-in method __new__ of type object at 0x560415201d60>)
20869 0.02831 1.357e-06 0.02831 1.357e-06 ~:0(<method 'reshape' of 'numpy.ndarray' objects>)