hi, I try to run the tutorial example in two machines.
One is my local mac(IP: 192.168.1.57), the other is a docker container(ubuntu) in a linux server(server IP: 192.168.60.67). I use a vpn to visit the server from my mac.
When creating the container, I mapped its port 60000(available) to the same port of the server. I want to first create a remote parameter server process(rank0) on the container, and a local worker process(rank1) on my mac. Then the worker will send some objects to the server, through the special address and port(“192.168.60.67:60000”).
The code:
#!/usr/bin/env python
# coding:utf-8
import argparse
import os
import time
from threading import Lock
import torch
import torch.distributed.autograd as dist_autograd
import torch.distributed.rpc as rpc
import torch.multiprocessing as mp
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.distributed.optim import DistributedOptimizer
from torch.distributed.rpc import BackendType
from torchvision import datasets, transforms
# --------- MNIST Network to train, from pytorch/examples -----
class Net(nn.Module):
def __init__(self, num_gpus=0):
super(Net, self).__init__()
print(f"Using {num_gpus} GPUs to train")
self.num_gpus = num_gpus
device = torch.device(
"cuda:0" if torch.cuda.is_available() and self.num_gpus > 0 else "cpu")
print(f"Putting first 2 convs on {str(device)}")
# Put conv layers on the first cuda device, or CPU if no cuda device
self.conv1 = nn.Conv2d(1, 32, 3, 1).to(device)
self.conv2 = nn.Conv2d(32, 64, 3, 1).to(device)
# Put rest of the network on the 2nd cuda device, if there is one
if "cuda" in str(device) and num_gpus > 1:
device = torch.device("cuda:1")
print(f"Putting rest of layers on {str(device)}")
self.dropout1 = nn.Dropout2d(0.25).to(device)
self.dropout2 = nn.Dropout2d(0.5).to(device)
self.fc1 = nn.Linear(9216, 128).to(device)
self.fc2 = nn.Linear(128, 10).to(device)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
# Move tensor to next device if necessary
next_device = next(self.fc1.parameters()).device
x = x.to(next_device)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# --------- Helper Methods --------------------
def call_method(method, rref, *args, **kwargs):
return method(rref.local_value(), *args, **kwargs)
def remote_method(method, rref, *args, **kwargs):
args = [method, rref] + list(args)
return rpc.rpc_sync(rref.owner(), call_method, args=args, kwargs=kwargs)
# --------- Parameter Server --------------------
class ParameterServer(nn.Module):
def __init__(self, num_gpus=0):
super().__init__()
model = Net(num_gpus=num_gpus)
self.model = model
self.input_device = torch.device(
"cuda:0" if torch.cuda.is_available() and num_gpus > 0 else "cpu")
def forward(self, inp):
inp = inp.to(self.input_device)
out = self.model(inp)
# This output is forwarded over RPC, which as of 1.5.0 only accepts CPU tensors.
# Tensors must be moved in and out of GPU memory due to this.
out = out.to("cpu")
return out
# Use dist autograd to retrieve gradients accumulated for this model.
# Primarily used for verification.
def get_dist_gradients(self, cid):
grads = dist_autograd.get_gradients(cid)
# This output is forwarded over RPC, which as of 1.5.0 only accepts CPU tensors.
# Tensors must be moved in and out of GPU memory due to this.
cpu_grads = {}
for k, v in grads.items():
k_cpu, v_cpu = k.to("cpu"), v.to("cpu")
cpu_grads[k_cpu] = v_cpu
return cpu_grads
# Wrap local parameters in a RRef. Needed for building the
# DistributedOptimizer which optimizes paramters remotely.
def get_param_rrefs(self):
param_rrefs = [rpc.RRef(param) for param in self.model.parameters()]
return param_rrefs
# The global parameter server instance.
param_server = None
# A lock to ensure we only have one parameter server.
global_lock = Lock()
def get_parameter_server(num_gpus=0):
"""
Returns a singleton parameter server to all trainer processes
"""
global param_server
# Ensure that we get only one handle to the ParameterServer.
with global_lock:
if not param_server:
# construct it once
param_server = ParameterServer(num_gpus=num_gpus)
return param_server
def run_parameter_server(rank, world_size):
print("PS master initializing RPC")
rpc.init_rpc(name="parameter_server", rank=rank, world_size=world_size)
print("RPC initialized! Running parameter server...")
rpc.shutdown()
print("RPC shutdown on parameter server.")
# --------- Trainers --------------------
class TrainerNet(nn.Module):
def __init__(self, num_gpus=0):
super().__init__()
self.num_gpus = num_gpus
self.param_server_rref = rpc.remote(
"parameter_server", get_parameter_server, args=(num_gpus,))
def get_global_param_rrefs(self):
remote_params = remote_method(
ParameterServer.get_param_rrefs,
self.param_server_rref)
return remote_params
def forward(self, x):
model_output = remote_method(
ParameterServer.forward, self.param_server_rref, x)
return model_output
def run_training_loop(rank, num_gpus, train_loader, test_loader):
# Runs the typical nueral network forward + backward + optimizer step, but
# in a distributed fashion.
net = TrainerNet(num_gpus=num_gpus)
# Build DistributedOptimizer.
param_rrefs = net.get_global_param_rrefs()
opt = DistributedOptimizer(optim.SGD, param_rrefs, lr=0.03)
for i, (data, target) in enumerate(train_loader):
with dist_autograd.context() as cid:
model_output = net(data)
target = target.to(model_output.device)
loss = F.nll_loss(model_output, target)
if i % 5 == 0:
print(f"Rank {rank} training batch {i} loss {loss.item()}")
dist_autograd.backward(cid, [loss])
# Ensure that dist autograd ran successfully and gradients were
# returned.
assert remote_method(
ParameterServer.get_dist_gradients,
net.param_server_rref,
cid) != {}
opt.step(cid)
print("Training complete!")
print("Getting accuracy....")
get_accuracy(test_loader, net)
def get_accuracy(test_loader, model):
model.eval()
correct_sum = 0
# Use GPU to evaluate if possible
device = torch.device("cuda:0" if model.num_gpus > 0
and torch.cuda.is_available() else "cpu")
with torch.no_grad():
for i, (data, target) in enumerate(test_loader):
out = model(data, -1)
pred = out.argmax(dim=1, keepdim=True)
pred, target = pred.to(device), target.to(device)
correct = pred.eq(target.view_as(pred)).sum().item()
correct_sum += correct
print(f"Accuracy {correct_sum / len(test_loader.dataset)}")
# Main loop for trainers.
def run_worker(rank, world_size, num_gpus, train_loader, test_loader):
print(f"Worker rank {rank} initializing RPC")
options = rpc.ProcessGroupRpcBackendOptions(
num_send_recv_threads=8,
rpc_timeout=0,
init_method="tcp://192.168.60.67:60000"
)
rpc.init_rpc(
backend=BackendType.PROCESS_GROUP,
# backend=rpc.BackendType.TENSORPIPE,
name=f"trainer_{rank}",
rank=rank,
world_size=world_size,
# rpc_backend_options=options,
)
print(f"Worker {rank} done initializing RPC")
run_training_loop(rank, num_gpus, train_loader, test_loader)
rpc.shutdown()
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description="Parameter-Server RPC based training")
parser.add_argument(
"--world_size",
type=int,
default=2,
help="""Total number of participating processes. Should be the sum of
master node and all training nodes.""")
parser.add_argument(
"--rank",
type=int,
default=0,
help="Global rank of this process. Pass in 0 for master.")
parser.add_argument(
"--num_gpus",
type=int,
default=2,
help="""Number of GPUs to use for training, Currently supports between 0
and 2 GPUs. Note that this argument will be passed to the parameter servers.""")
parser.add_argument(
"--master_addr",
type=str,
default="localhost",
help="""Address of master, will default to localhost if not provided.
Master must be able to accept network traffic on the address + port.""")
parser.add_argument(
"--master_port",
type=str,
default="29500",
help="""Port that master is listening on, will default to 29500 if not
provided. Master must be able to accept network traffic on the host and port.""")
args = parser.parse_args()
assert args.rank is not None, "must provide rank argument."
assert args.num_gpus <= 3, f"Only 0-2 GPUs currently supported (got {args.num_gpus})."
os.environ['MASTER_ADDR'] = args.master_addr
os.environ["MASTER_PORT"] = args.master_port
processes = []
world_size = args.world_size
if args.rank == 0:
p = mp.Process(target=run_parameter_server, args=(0, world_size))
p.start()
processes.append(p)
else:
# Get data to train on
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=32, shuffle=True, )
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(
'./data',
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=32,
shuffle=True,
)
# start training worker on this node
p = mp.Process(
target=run_worker,
args=(
args.rank,
world_size, args.num_gpus,
train_loader,
test_loader))
p.start()
processes.append(p)
for p in processes:
p.join()
First I run the above code(tutorial.py) in the remote container to create a server process :
python tutorial.py --rank=0 --num_gpus=2 --master_addr="localhost" --master_port="60000" --world_size=2
Second I run the same code in my mac to create the worker process, with some different args:
python tutorial.py --rank=1 --num_gpus=2 --master_addr="192.168.60.67" --master_port="60000" --world_size=2
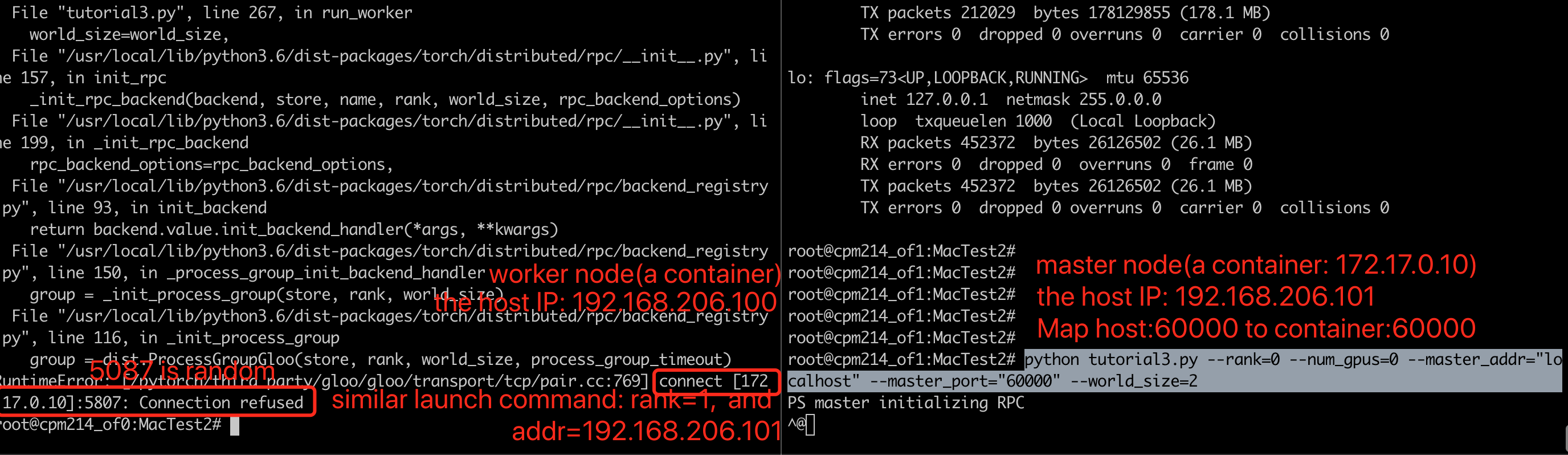
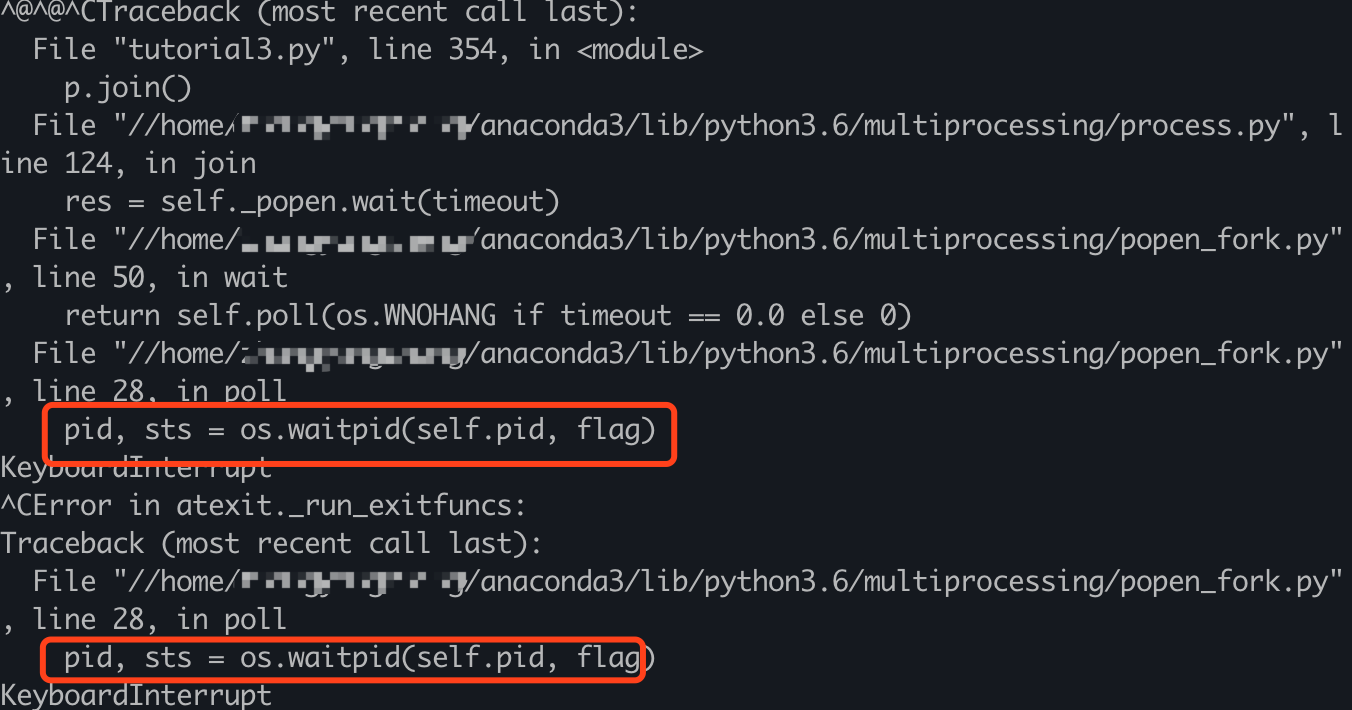
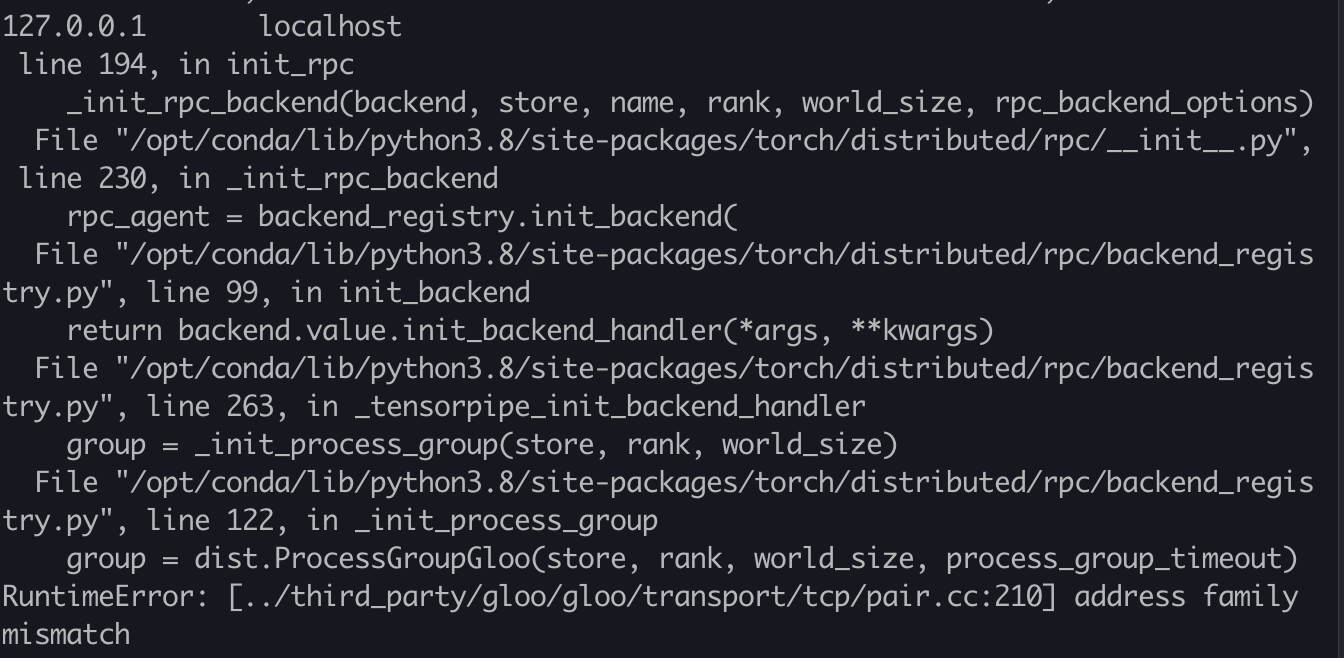
One error occurs in both nodes.
In the container:
In my mac:
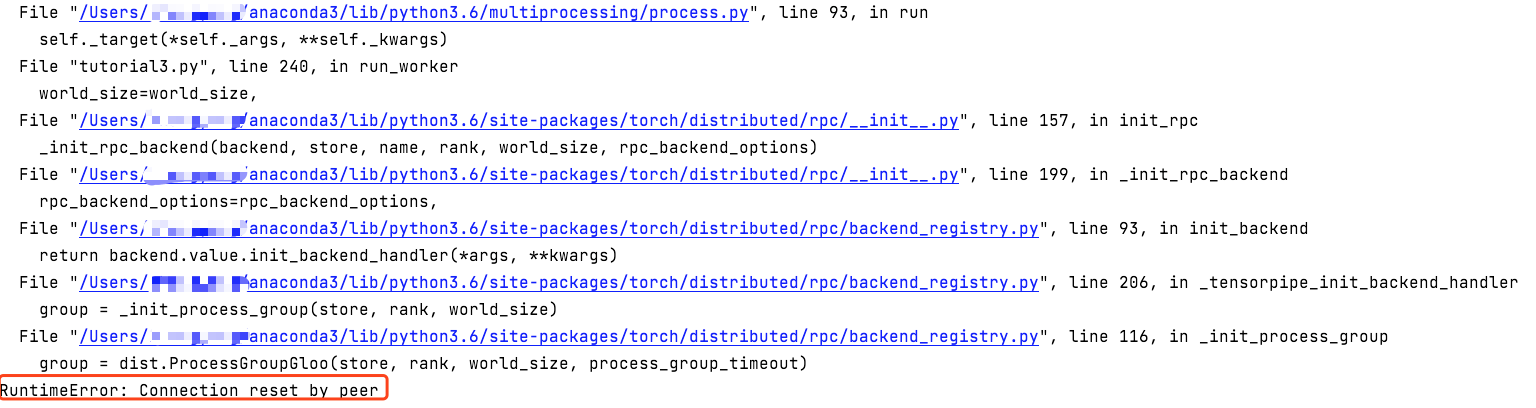
I change the master_addr in first comand line to “127.0.0.1” or “192.168.60.67”, but it’s the same error.
Also I set the special environment variables, but it does not work:
# in container
export GLOO_SOCKET_IFNAME=eth0,lo
export TP_SOCKET_IFNAME=eth0,lo
# in mac
export GLOO_SOCKET_IFNAME=en0,lo
export TP_SOCKET_IFNAME=en0,lo
Any advice would be appreciated, thanks.