Dear Mr. Ptrblck,
Hi, I have run the example, but I still have two other questions:
1. I am not sure if the above example makes fc1’weight without gradient update or the weights set to 0 without gradient update.
This is my result of the example:
Step 2, weight Parameter containing:
tensor([[ 5.8677e-01, 1.6791e-02, -1.0280e-03, -1.4700e+00],
[ 1.5483e-01, -6.6316e-01, 4.2021e-01, 1.2349e+00],
[-3.2102e-02, -5.1647e-02, -2.1887e-02, -1.1000e-03],
[ 6.9480e-04, 6.0782e-02, 6.0572e-02, 5.4448e-02],
[-6.6701e-04, -4.8314e-03, 5.1907e-02, 5.2159e-02]],
requires_grad=True),
weight.grad tensor([[-0.1711, -0.1190, -0.0521, -0.0074],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[-0.0137, -0.0095, -0.0042, -0.0006],
[-0.0104, -0.0072, -0.0032, -0.0005]])
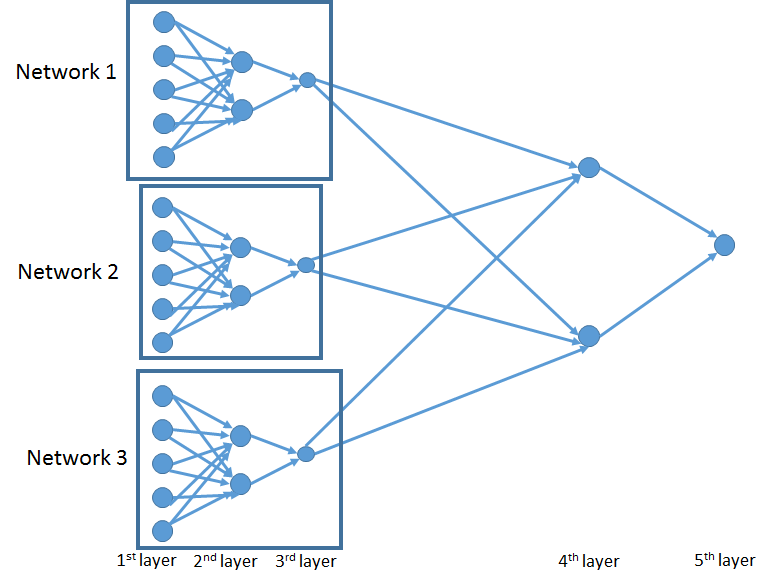
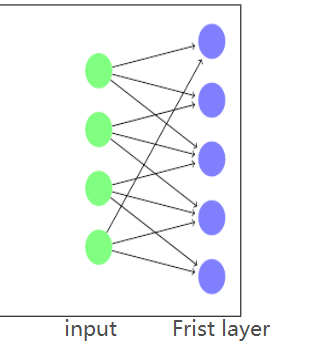
2. If this model is very large, then the mask will be difficult to define. Have any example similar like the LocallyConnected1D?
Thank you so much!!!
Infinite gratitude!!!