Hi @ptrblck
I finally found out what was going wrong. It wasn’t NN model related.
In the end, it turned out that there might have been three issues.
- With torch you have data conversion from numpy to a torch tensor, and data movement from cpu to gpu.
When you need to compute the metrics, one has to take care about calculating the metrics (loss, accuracy), in either numpy or torch. In my train and eval loops, because the CS230 template initially used numpy (after moving it from the GPU using calling tensor.cpu(), and then converting it to numpy, using tensor.numpy()), and mid-way I used a Torch version of the BCEDiceLoss and Dice coefficient, the metrics were off and the NN couldn’t learn anything.
Numpy uses HxWxC ordering, whereas PyTorch uses CxHxW ordering.
- In the original code, when working with the GPU, the train and labels batch are not explicitly cast to Torch Variables.
Q01: Would this have had any impact?
# Use tqdm for progress bar
with tqdm(total=len(dataloader)) as t:
for i, (train_batch, labels_batch) in enumerate(dataloader):
# move to GPU if available
if params.cuda:
train_batch, labels_batch = train_batch.cuda(async=True), labels_batch.cuda(async=True)
# convert to torch Variables
train_batch, labels_batch = Variable(train_batch), Variable(labels_batch)
I modified it as follows, casting both the GPU case and the CPU case to use torch variables.
# iterate over the data, use tqdm for progress bar
with tqdm(total=len(dataloader), desc="training") as t:
for i, samples_batch in enumerate(dataloader):
# extract data and labels batch
train_batch = samples_batch['image']
labels_batch = samples_batch['mask']
# convert to torch variables, move to GPU if available
if params.cuda:
train_batch = Variable(train_batch.cuda(async=True))
labels_batch = Variable(labels_batch.cuda(async=True))
else:
train_batch = Variable(train_batch)
labels_batch = Variable(labels_batch)
- When I used the model with an LR scheduler, I forgot to update the step for the LR scheduler, thinking calling step on the scheduler would automatically call step on the optimizer. This could have been another reason why the model didn’t progress training further.
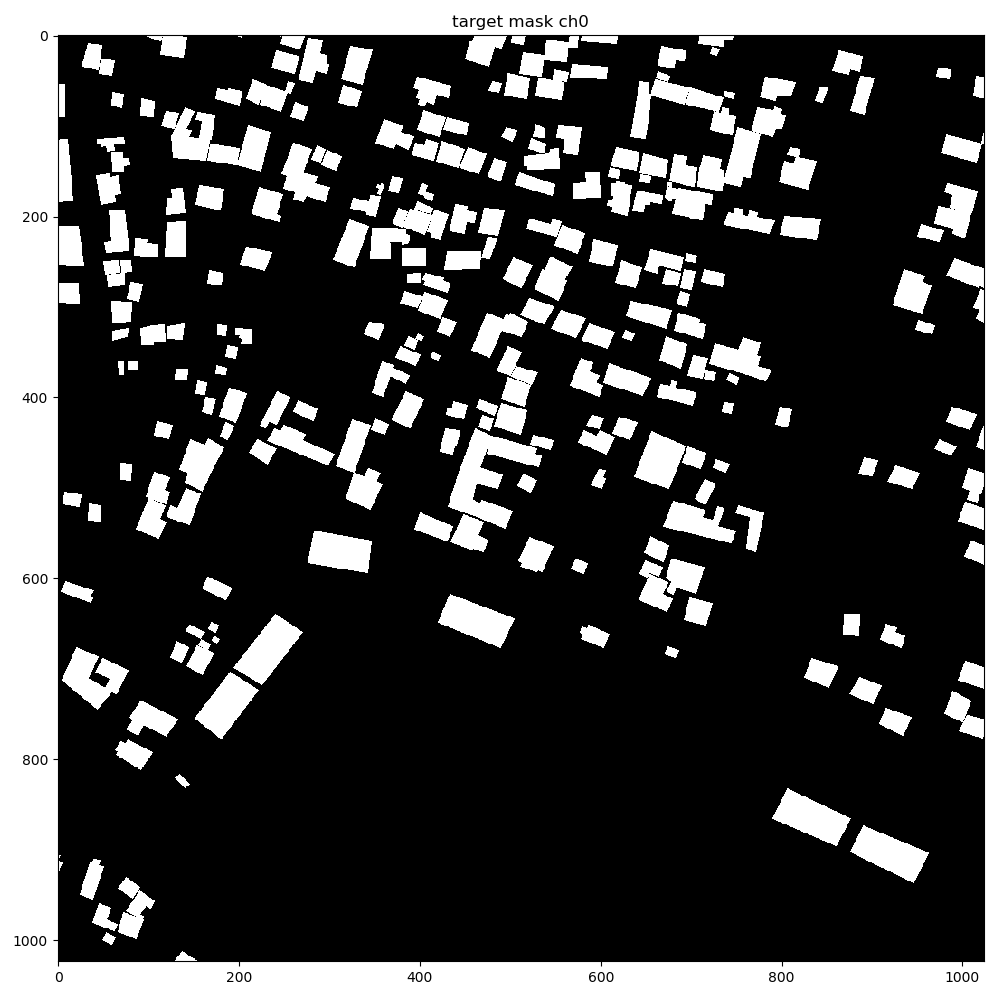
The NN is beginning to pick out the buildings now.
These are the predictions during train:
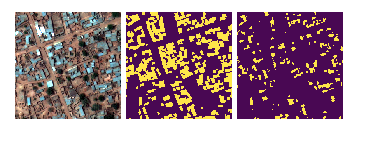
These are the predictions during validation.