rchavezj
June 20, 2018, 10:01pm
1
Hello Everyone!
I’ve been working on deploying a machine learning model (Pytorch) into production (iOS), however I’m having a few obstacles I need to hurdle. I tried following the steps here (GitHub - longcw/pytorch2caffe: Convert PyTorch model to Caffemodel ) to convert it to either caffe2 or ONNX (GitHub - onnx/onnx-coreml: ONNX to Core ML Converter ), knowing the input_size is required to make a forward pass through the network.
I keep getting an error with the forward function that was from the text_encoder RNN model.
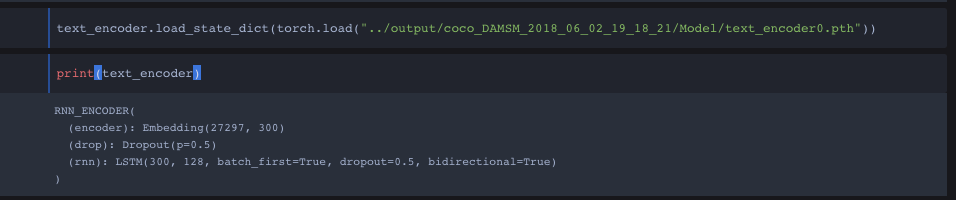
The text_encoder is a machine learning model I loaded (Followed these steps: python - How do I save a trained model in PyTorch? - Stack Overflow ) from another program file I used to train on.
I’m not sure if I’m either getting the error from Dimension mis-match or not properly calling enough arguments for my forward function. Any help is greatly appreciated!
Diego
June 20, 2018, 11:30pm
2
EDIT:
EDIT #2: migration guide to make your code cleaner and compatible with future releases
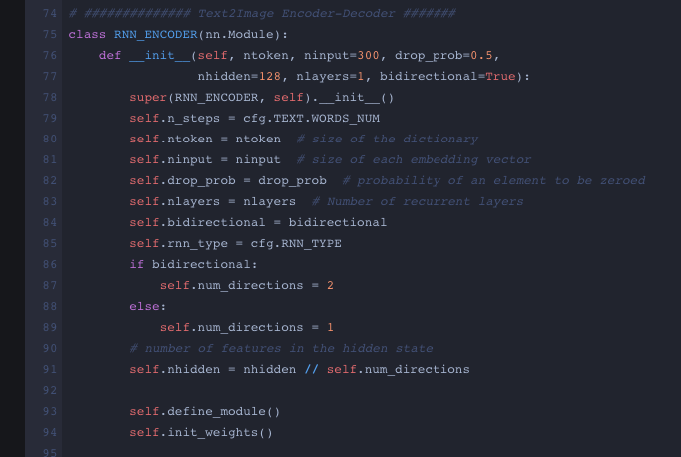
I think the problem is, you are using dropout with only one layer. You need at least 2 layers to apply dropout if you are using the LSTM class. You can check the documentation here . It says:
dropout – If non-zero, introduces a Dropout layer on the outputs of each LSTM layer except the last layer, with dropout probability equal to dropout. Default: 0
best regards,
1 Like
rchavezj
June 20, 2018, 11:37pm
4
I’ll check out the documentation and get back to you shortly. Thank you for the starting point!
Diego
June 20, 2018, 11:48pm
5
I think the cause of the error is you call your forward function like so:
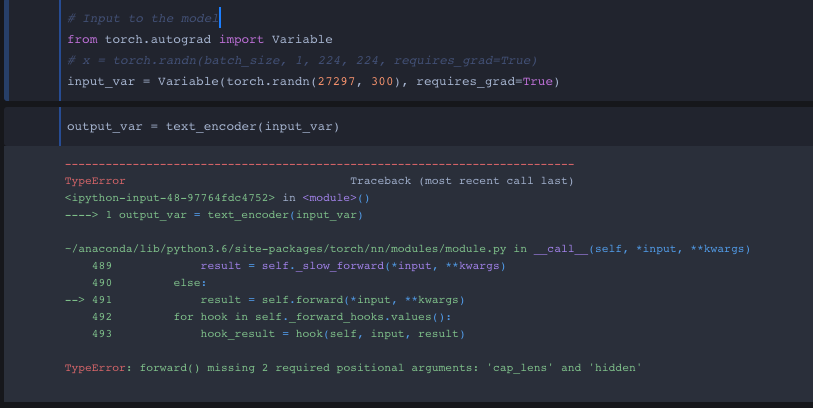
output_var = text_encoder(input_var)
Yet your forward function is defined as:
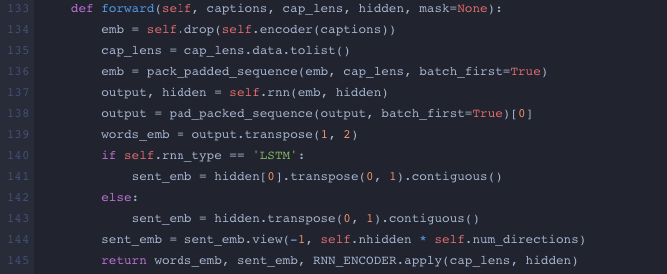
def forward(self, captions, cap_lens, hidden, mask=None)
You are only passing 2 parameters (self, input_var) to your forward function but it needs at least 4.
best regards,
1 Like
rchavezj
June 21, 2018, 9:27pm
6
What values of cap_lens & hidden should i use for replicating a loaded model?
Diego
June 21, 2018, 9:41pm
7
From your code its is unclear to me what these parameters represent, could you post the others methods were these variables are used?
rchavezj
June 21, 2018, 9:58pm
8
Are you referring to input_var using a Variable keyword? Instead of
input_var = Variable(torch.randn(27297, 300), requires_grad=True)I should have it as
input_var = torch.randn(27297, 300)What Happens with
requires_grad=True?
Diego
June 21, 2018, 10:31pm
9
You should do it like so:
input_var = torch.randn(27297, 300, requires_grad=True)
remember to check the migration guide
This is not the root of your problem though
rchavezj
June 23, 2018, 8:47pm
11
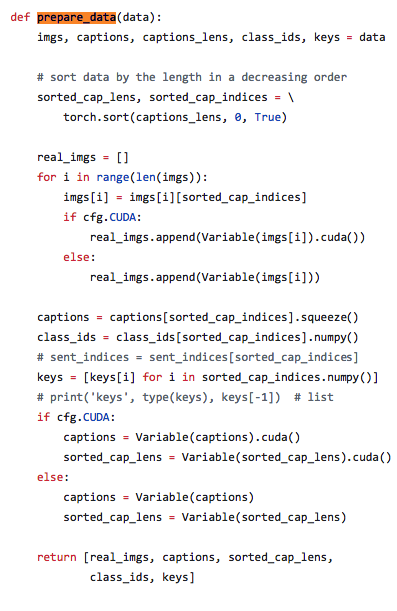
I’m using this git repo (GitHub - taoxugit/AttnGAN ) for cap_lens and the hidden variable. Their located inside AttnGAN/code/pretrain_DAMSM.py @line_65
however they were generated data (prepare_data) from the class AttnGAN/code/datasets.py @line_28