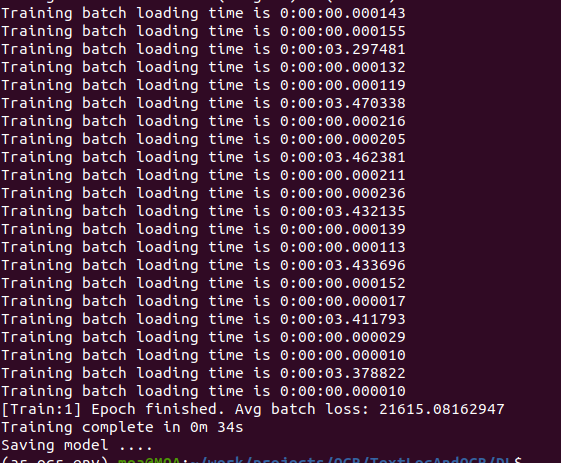
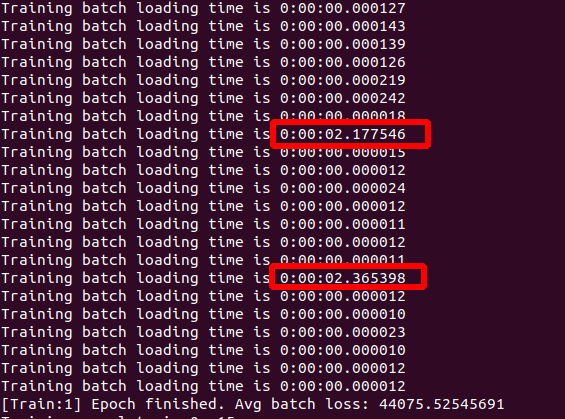
I have the same problem reported in the post Different batches take different times to load. I am using 3 workers Dataloading workers for loading images from a local folder. And as you can see below, it seems to me that one worker is constantly having a slower time than the other two.
The accepted answer suggests using SSD, which is true in my case. Also suggests increasing the number of workers. When I increased the num_workers=8, I observed the same pattern, where every 8 batches, one of them is constantly taking more time to load.
Below is my code for loading. Is there anything missing or optimizations that I need to make to fix this?
But are you saying that my data loading is slow compared with training loop time, or you mean that I have an issue with MyDataset class?
What I understand from the discussion, that in my case, there is no way to avoid this other than increasing the number of workers to the limit that makes their loading time hidden compared with the training loop time. Please correct my understanding.
which would reuse the underlying data (assuming self.datasets returns a numpy array).
Yes, that’s correct and you would have to either speed up the data loading (or increase the workload for the model training).
Note that, the smaller the GPU workload is, the more likely you’ll hit a data loading bottleneck.
In the extreme case that your model immediately trains an iteration (just remove the model training), you would have to make sure that the data loading is fast enough to load and process the next batch while Python “executes the loop” (which would be fast as there is no real workload).
You are right, increasing the num_workers would enhance the performance. But not if I am using a distributed training, I noticed that in the case of distributed training (DistributedDataParallel) increasing num_workers is hindering performance. I reported a similar problem in this post.