with Chien-Chin Huang (@fegin), Less Wright (@lessw2020), Tianyu Liu (@tianyu), Will Constable (@wconstab), Gokul Nadathur (@gnadathur)
TL;DR
-
We implemented pass-KV Ring Attention for Context Parallel in PyTorch
-
We integrated it in torchtitan and verified its effectiveness as well as composability with other native techniques in PyTorch such as FSDP and torch.compile
-
Sequence length scaling to 1M on Llama3-8B model using 32 H100 GPUs
-
Matching loss curves with existing parallelisms
-
Compatible with torch.compile. The compile mode provides an average 10% TPS gain on a set of benchmarks
-
Distributed with TorchTitan Series
The GitHub repository torchtitan is a proof of concept for large-scale LLM training using native PyTorch, designed to be easy to understand, use, and extend for different training purposes, supporting multi-dimensional parallelisms with modular components. In this series of topics, we introduce the latest PyTorch features for distributed training enabled in Torchtitan.
-
Topic 1: Enabling Float8 All-Gather in FSDP2
-
Topic 3: Optimizing Checkpointing Efficiency with PyTorch DCP
-
→ Topic 5: Breaking Barriers: Training Long Context LLMs with 1M Sequence Length in PyTorch Using Context Parallel
Context Parallel
Context Parallel is an approach used in LLM to reduce peak activation size by sharding the long input sequence across multiple devices. It breaks the constraint on input sequence length resulting from peak memory usage on storing activations in Transformer blocks.
The core of Context Parallel is Ring Attention, a novel parallel implementation of the Attention layer. Ring Attention shuffles the KV shards and calculates the partial attention scores, repeats until all KV shards have been used on each device. This shard shuffling can be done via either multiple p2p send/recv between devices, or one allgather. This sequence length scaling is claimed to be zero-overhead if the shard rotation among devices overlaps well with the attention computation over local QKV shards.
The overview of Ring Attention algorithm is below:
# Ring Attention algorithm
N: number of devices where QKV is sharded.
Q_i; K_i; V_i: the QKV shard placed on device i
# on device i
for j in 1..N:
Collect K_j and V_j from other device
Compute Attention(Q_i, K_j, V_j)
Enabling Context Parallel
It is actually pretty easy to automatically replace Attention layers with Ring Attention and utilize Context Parallel in users’ model code. We provide a public API context_parallel which takes in several arguments regarding how to parallelize SDPA and returns a Python context within which the SDPA function will be replaced with an equivalent Ring Attention.
Enabling Context Parallel in model code is quite simple and only takes two steps:
- Create a Context Parallel context for each training/inference step
- Wrap the forward/backward pass using the context
while step < job_config.training.steps: # training loop
step += 1
# Step 1:
# create a context parallel python context for current training step
context_parallel_ctx = context_parallel(...)
# Step 2:
# wrap training/inference code in the context
with train_context(context_parallel_ctx): # enable Context Parallel
# no changes to model code needed!!
pred = model(input_ids)
loss = loss_fn(pred, labels)
loss.backward()
Now let’s dive into an end-to-end example of adopting Context Parallel in Long-context LLMs training in PyTorch.
Long-context Training in Torchtitan
We enabled Context Parallel in torchtitan to verify the effectiveness and composability of our implementation and showcase how Context Parallel can be easily enabled in user code.
First of all, just like other parallelisms adopted in torchtitan, there’s no change needed for the model code. All PyTorch SDPA function calls will be replaced with Ring Attention automatically.
# torchtitan/models/llama/model.py
# the model code remains untouched
class Attention(nn.Module):
def forward(self, x: torch.Tensor, ...):
...
output = F.scaled_dot_product_attention(xq, xk, xv, is_causal=True) # SDPA
...
Now, a number of GPUs need to be allocated to the Context Parallel device mesh dimensions.
# torchtitan/parallelisms/parallel_dims.py
# create Context Parallel device mesh from parsed config file
world_mesh = init_device_mesh(
device_type,
mesh_shape=...,
mesh_dim_names=(..., "cp", ...),
)
cp_mesh = world_mesh["cp"]
# create "dp_shard_cp" mesh if composing with FSDP/HSDP
if DP:
world_mesh["dp_shard", "cp"]._flatten(mesh_dim_name="dp_shard_cp")
else:
world_mesh["cp"]._flatten(mesh_dim_name="dp_shard_cp") # equivalent
Leverage the FSDP API to shard module parameters and install hooks that all-gather parameters before forward pass and reduce-scatter to sync gradients.
# torchtitan/parallelisms/parallelize_llama.py
# parallelize the model through FSDP fully_shard API
dp_mesh_dim_names = []
if HSDP:
dp_mesh_dim_names.append("dp_replicate")
dp_mesh_dim_names.append("dp_shard_cp")
apply_fsdp(
model,
world_mesh[tuple(dp_mesh_dim_names)],
cpu_offload=job_config.training.enable_cpu_offload,
...
)
The last step is creating the python context for Context Parallel every step and putting the model forward and backward in the context so that the input tensor will be automatically sharded and SDPA will be replaced with Ring Attention.
# train.py
# enable context parallel in model training code
def main(job_config: JobConfig):
... # init
while step < job_config.training.steps: # training loop
step += 1
... # data loading, etc..
# create a context parallel python context for current training step
context_parallel_ctx = context_parallel(
cp_mesh=world_mesh["cp"],
cp_buffers=[input_ids, labels, ...],
cp_seq_dims=[1, 1, ...], # shard on seq dimension
cp_no_restore_buffers={input_ids, labels}, # don't restore
cp_rotate_method=job_config.experimental.context_parallel_rotate_method, # shard rotation
)
with train_context(context_parallel_ctx): # enable Context Parallel
pred = model(input_ids)
loss = loss_fn(pred, labels)
del pred
loss.backward()
With the above changes in torchtitan, we can simply turn on Context Parallel in torchtitan by modifying the “context_parallel_degree” field in the .toml config file. For example, we want to use Ring Attention and allocate 8 GPUs for every Context Parallel group when running the llama3-70B model in torchtian. We can do the following:
# file: llama3_70b.toml
[experimental]
context_parallel_degree = 8 # use 8 GPUs for each Context Parallel group
Composing Context Parallel With Data Parallel
If users want to compose Context Parallel with Data Parallel (FSDP or HSDP) in PyTorch, there’s one more step: users need to create a joint DeviceMesh of Data Parallel dimension and Context Parallel dimension. Data Parallel dimension refers to the data parallel groups for FSDP and the data parallel groups that would actually shard model weights for HSDP.
# example: create a device mesh from HSDP and Context Parallel mesh dimensions
from torch.distributed.device_mesh import init_device_mesh
# organize 8-GPU into 3 device mesh dimensions
world_mesh = init_device_mesh(
device_type,
mesh_shape=[[[0, 1], [2, 3]], [[4, 5], [6, 7]]],
mesh_dim_names=("dp_replicate", "dp_shard", "cp"),
)
hsdp_mesh = world_mesh["dp_replicate", "dp_shard"]
cp_mesh = world_mesh["cp"]
# flatten "dp_shard" and "cp" into the "dp_shard_cp" mesh, over which the
# weight all-gather and grads sync reduce-scatter in FSDP/HSDP is performed
world_mesh["dp_shard", "cp"]._flatten(mesh_dim_name="dp_shard_cp")
Implementation Details
Ring Attention
We implemented Ring Attention in PyTorch and provide Context Parallel as a Python context where the user-specified tensor will be automatically sharded over the sequence-dim within the Context Parallel group and all ATEN scaled dot product attention op (at this moment we only support _scaled_dot_product_flash_attention and _scaled_dot_product_efficient_attention) will be replaced with our ring attention handler during op dispatching.
The implementation consists of several submodules:
- Tensor sharding
- Attention op dispatching
- Shard rotation
- Masking and load balancer
- SDPA merger
Tensor Sharding
This module is responsible for sharding the Input tensor to attention layers as well as labels and embeddings if present, within the Context Parallel group. Currently we adopt two sharding strategies: Sequential sharder and Round Robin sharder.
Sequential sharder evenly splits QKV into N contiguous blocks where N is the size of the Context Parallel group and shards one block to each rank.
Round Robin sharder is designed for Causal Masking. When Causal Masking is used, only the lower triangle part of QKV is needed for computation. This sharder evenly splits QKV into 2N blocks and shard the currently shortest block and longest block to rank 0, 1, …, N-1 (i.e. shard 0 and 2N-1 go to rank 0, shard 1 and 2N-2 go to rank 1, etc).
Attention Op Dispatching
The replacement of PyTorch scaled dot product attention (SDPA) with Ring Attention takes two steps:
- Install hooks to SDPA function to convert input from torch.Tensor to DTensor
- Replace ATEN SDPA ops with Ring Attention
With the above change, all SDPA function calls within the Context Parallel Python context are seamlessly replaced with a Ring Attention implementation.
Shard Rotation
Rotating QKV shards within the Context Parallel group between local SDPA calls instead of applying a single SDPA to the whole input batch is the key change in Ring Attention. How well this data communication can be overlapped with local SDPA computation dominates the scaling overhead. If the communication can be well hidden, the scaling will be zero-overhead.
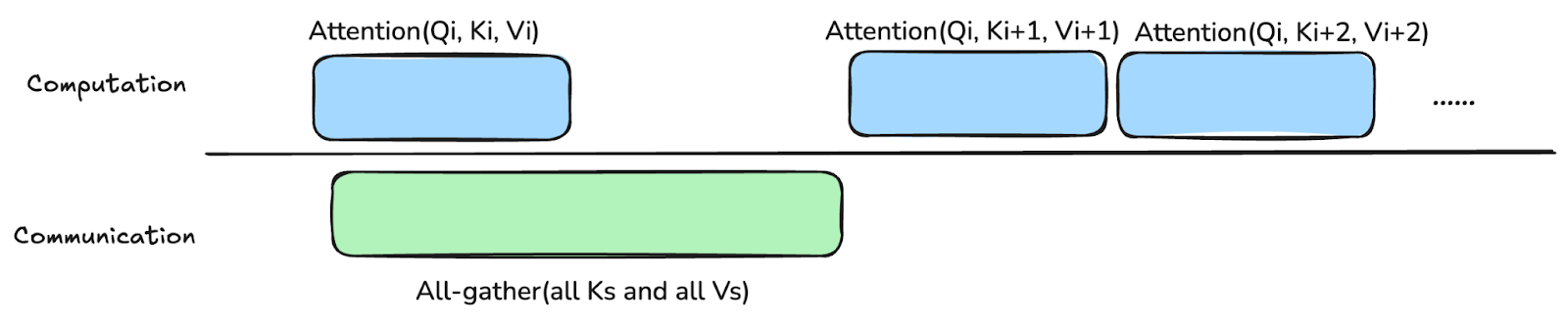
We offer two strategies of rotating the QKV shards within the group: ring rotation using all-to-all collective between each local SDPA, or collect all shards using all-gather before launching the first local SDPA.
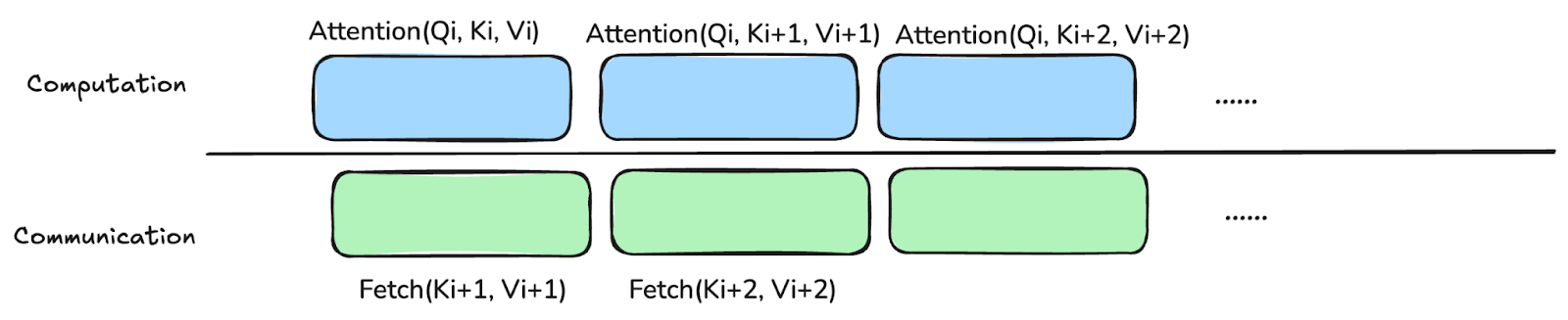
- Ring rotation using all-to-all between local SDPAs: ring Attention starts at a state where each Context Parallel rank holds a shard of QKV tensor. The first rotation happens when the first local SDPA is launched, and each rank passes its local shard to the next rank in a ring style: rank i passes to rank i+1 and the last rank passes to rank 0. Ideally this rotation is completed before the next local SDPA is about to launch. This iteration repeats until a shard has been passed throughout the ring.
Figure 1. Ideal Comp-Comm overlapping in all-to-all based Context Parallel
- All-gather all shards ahead of the first local SDPA: each rank still only holds one QKV shard when Ring Attention starts. However, each rank calls all-gather to collect the shards from other ranks. Then each rank first launches local SDPA on its own local QKV shard, selects the next shard from the all-gathered shards for its next local SDPA, and repeats until all shards have been used.
Figure 2. Ideal Comp-Comm overlapping in all-gather based Context Parallel
We did a simple profiling on the Llama3-8B model on 8 H100 GPUs with Context Parallel degree 8 to gain the trace of both rotation approaches and see which approach performs better. When profiling, we disabled torch.compile and activation checkpointing. And the sequence length and local batch size are 8k and 1 correspondingly.
All-to-All: The all-to-all collective which is necessary for the next SDPA computation does overlap with the current SDPA. However, in this case the collective cost is too high (~470 us) and cannot be fully overlapped.
Figure 3. CPU thread trace of Context Parallel using all-to-all

Figure 4. CUDA stream trace of Context Parallel using all-to-all

All-gather: The situation is similar to the all-to-all case except there’s only one all-gather needed while the all-to-all approach needs to issue N-1 collectives where N is the Context Parallel degree.
Figure 5. CPU thread trace of Context Parallel using all-gather

Figure 6. CUDA stream trace of Context Parallel using all-gather
We choose the All-gather approach as the default rotation approach for the following reasons:
- The all-gather approach is simpler and easier to tune performance because it has less collectives. This is especially true when Context Parallel spans over multiple hosts.
- The all-to-all approach requires full overlap for best performance and the penalty for exposing is higher than the all-gather one.
Causal Masking and Load Balancer
Just as PyTorch scaled_dot_product_attention, we support Causal Masking in our Ring Attention. If users have is_causal=True in their model code, the replacing Ring Attention will also use Causal Masking.
Since a lower triangular masking will be applied to the attention scores if the causal masking is specified, the local SDPA can be optimized to save computation by applying to a part of the QKV shard only. However, this also leads to the imbalance of computation among local SDPAs, and prohibits a good overlap of data communication and computation.
To remedy this problem, we also implemented a Round Robin Load Balancer which shards the shortest query block and the longest one to rank 0, then the second shortest query block and the second longest one to rank 1, and so on. The length variance of query blocks comes from the triangularity of the causal mask.
If is_causal=False, a Sequential sharder is used instead, which shards one contiguous QKV block to each rank within the Context Parallel group.
SDPA Merger
This module is responsible for calculating the output and log_sumexp from the results of local SDPAs (the ATEN op). Note that the merging formula is slightly different for the Causal Masking case.
Experimental Methodology
We first used torchtitan’s Llama3-8B model to verify the experimental Context Parallel feature and verify the composability. Then we used torchtitan’s LLama3-70B model to understand the benefit of using torch.compile with Context Parallel. The benchmark was performed on a cluster where each host has 8 H100 Nvidia GPUs.
Evaluation
Sequence Length Scaling
To measure the longest possible sequence length under our experiment setup, we fix the local batch size to 1 and modify the input sequence length and Context Parallel degree (i.e. group size).
We want to show the effectiveness of our implementation in several aspects:
- To measure the longest possible sequence length we can achieve w/o OOM, we turned off torch.compile in this case because it introduces memory usage imbalance across GPUs where some ranks have significantly higher memory footprint than others. We suspect this is related to our causal masking and load balance not working well with torch.compile.
- When doubling the Context Parallel degree, the max sequence length without causing OOM doubles.
- When seq_length/context_parallel_degree is fixed, the memory usage is stable while MFU (Model FLOPS Utilization) drops because of intra-host communication.
- The all-gather approach has better performance in the multi-host case because it issues less communications.
| seq_length | 256K | 512K | 1M |
|---|---|---|---|
| all-to-all | MEM: 81.01GiB TPS: 781 MFU: 36.11% |
MEM: 77.11GiB TPS: 196 MFU: 17.22% |
MEM: 75.73GiB TPS: 70 MFU: 12.05% |
| all-gather | MEM: 82.89GiB TPS: 706 MFU: 32.64% |
MEM: 75.65GiB TPS: 320 MFU: 28.16% |
MEM: 66.62GiB TPS: 150 MFU: 25.66% |
| Required CP degree | 8 | 16 | 32 |
Table 1. max seq_len scaling vs. Context Parallel degree
Figure 7. peak memory usage of training long context data with Context Parallel

Figure 8. MFU of training long context data with Context Parallel

Figure 9. TPS of training long context data with Context Parallel

Composability With Other Parallelisms
So far, we already have many types of parallelisms in PyTorch that can be adopted in transformer model training such as FSDP/HSDP, Tensor Parallel, and Pipeline Parallel. It’s critical for our Context Parallel to work seamlessly with those techniques, therefore we tested the composability with them by launching test training jobs and observing the loss converging trend. Below is a collection of verified combinations of parallelism on Llama3 8B in torchtitan. The verification requires the loss converging curve shows a close match with the one from the non-CP training (e.g. if the combination is PP+FSDP+TP+CP, then the object of comparison is PP+FSDP+TP).
Each training job runs for 600 warm-up steps and 3,000 total steps. All verifications are performed with and without torch.compile. We verified Context Parallel works in combination with the following parallelisms:
- FSDP/HSDP
- Tensor Parallel (TP)
- FSDP/HSDP+TP
- Pipeline Parallel (PP) + FSDP/HSDP
- PP + FSDP/HSDP + TP
It’s worth note that for Pipeline Parallel we chose “Interleaved 1F1B” schedule instead of “Interleaved ZeroBubble” because Zero Bubble currently doesn’t work with torch.compile.
Compatibility With Torch.compile
The experience of using torch.compile w/ Context Parallel in torchtitan is smooth, and the user only needs to set “compile = true” in .toml file to turn on compiler mode.
To understand the impact of using torch.compile, we ran Llama3-70B model on 64 H100 GPUs for 20 steps, with and without torch.compile, and compared their peak memory usage and tokens per second (TPS). The Data Parallel degree is 8 and Context Parallel degree is also 8. We also vary the input sequence length from 8K to 128K to understand the impact over a broad spectrum of sequence size.
The result shows that when the sequence length is small, the peak memory usage is slightly higher and the TPS is significantly higher with the compile mode. When the sequence length is large, the peak memory usage and TPS are both lower with the compile mode. On average, the compile mode provides a 10% TPS gain with 2% memory usage regression.
Figure 10. peak memory usage of training long context data with torch.compile on 64 GPUs (FSDP+CP)

Figure 11. MFU of training long context data with torch.compile on 64 GPUs (FSDP+CP)

Figure 12. TPS of training long context data with torch.compile on 64 GPUs (FSDP+CP)

One of the reasons is sometimes the compiler decides to not overlap the SDPA computation and shard rotation. In this case, the compiler believes the shard rotation and the first SDPA call are data-dependent and decides to enforce the collective and computation being strictly separate.

Figure 13. CPU thread trace showing all-gather is correctly placed between the first and second SDPA call
Figure 14. CUDA stream showing all-gather is exposed
We plan to address this issue in future updates.
Conclusion
In conclusion, we introduced Context Parallel to PyTorch through the use of Ring Attention that allows users to train long-context LLMs without OOM. With Context Parallel, we successfully train Llama3-8B in torchtitan with 1 million sequence length. We also tested its composability with other PyTorch’s native features such as torch.compile, FSDP/HSDP, Tensor Parallel, and Pipeline Parallel, and Context Parallel works out-of-box with those features. Looking forward, we will continue to improve the Context Parallel on compatibility and performance. We welcome any contributions and suggestions from the community on this work.