with Andrew Gu, Wanchao Liang, Driss Guessous, Vasiliy Kuznetsov, Brian Hirsh
TL;DR
- We focus on float8 because it speeds up large GEMMs on H100s and saves network bandwidth with reduced message size.
- We enabled float8 all-gather in FSDP2. Readers can find training recipe for Llama3 in TorchTitan and float8 dtype implementation in TorchAO/float8 .
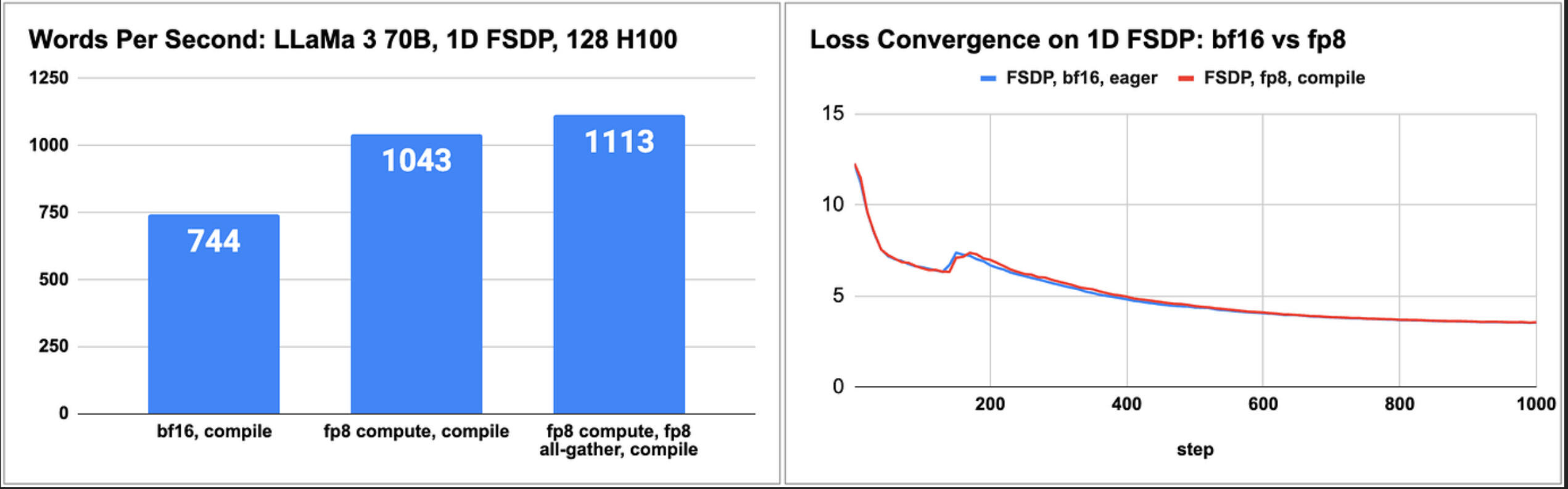
- We observed 1.50x speedup with float8 compared with bfloat16 with on-par numerics. 20% of the speedup is contributed by float8 all-gather while the rest 80% come from float8 compute. The result is benchmarked by pretraining Llama3-70B using 128 H100s*.
* Meta’s H100s are customized on Grand Teton . Specifications might be different to public ones.
Float8 Training and Why Float8 All-Gather Matters
Float8 data types are natively supported in NVIDIA H100. Float8 training enablement can be divided into 2 parts: float8 compute and float8 communication.
Float8 compute: support float8 matrix multiplication with torch._scaled_mm . Different from bfloat16, float8 requires both raw tensor and scales to preserve numeric accuracy. Users need to maintain scales in the training loop. There are different scaling strategies including tensor-wise scaling, row/col-wise, group-wise, and block-wise. In this note, we focus on tensor-wise scaling and dynamic scaling ref, where scales are computed from the current high-precision tensor.
Float8 communication (Float8 all-gather): with float8 compute, doing all-gathers in float8 is a almost a “free lunch” because we need to cast parameters before or after the all-gather. Casting before the all-gather saves 50% bandwidth (vs bfloat16) at the cost of one all-reduce for AMAX. Float8 can be applied to model weights, activations and gradients. We prioritized float8 weights since they are more stable numerically through the training loop and fit better with low-precision dtypes. We focus on Llama3 models in this note.
Readers can find training recipe for Llama3 in TorchTitan and float8 dtype implementation in TorchAO/float8 .
Applying FSDP2 to Llama3 with Float8 Weights
Float8 Model (code): PyTorch native float8 requires minimal changes to models. Taking Llama3-8B model as an example, we convert the bfloat16 model to a float8 model by swapping every nn.Linear with a Float8Linear , so that we can perform float8 compute.
TransformerBlock(
(attention): Attention(
(wq/wk/wv/wo): Float8Linear(in=4096, out=4096, bias=False)
)
(feed_forward): FeedForward(
(w1/w2/w3): Float8Linear(in=4096, out=14336, bias=False)
)
(attention_norm / ffn_norm): RMSNorm()
)
Applying FSDP2 (code): The UX of wrapping a float8 model is the same as wrapping a bfloat16 model. To keep track of scales efficiently, we call precompute_float8_dynamic_scale_for_fsdp after the optimizer step, so we can get replicated scales for float8 casting before float8 all-gather.
# wrapping each TransformerBlock, then root model
# the UX is the same across float8 model and bfloat16 model
for transformer_block in model.layers.values():
fully_shard(transformer_block)
fully_shard(model)
# training loop
# ...
optimizer.step()
# all-reduce AMAX for Float8Linear.weight
precompute_float8_dynamic_scale_for_fsdp(model)
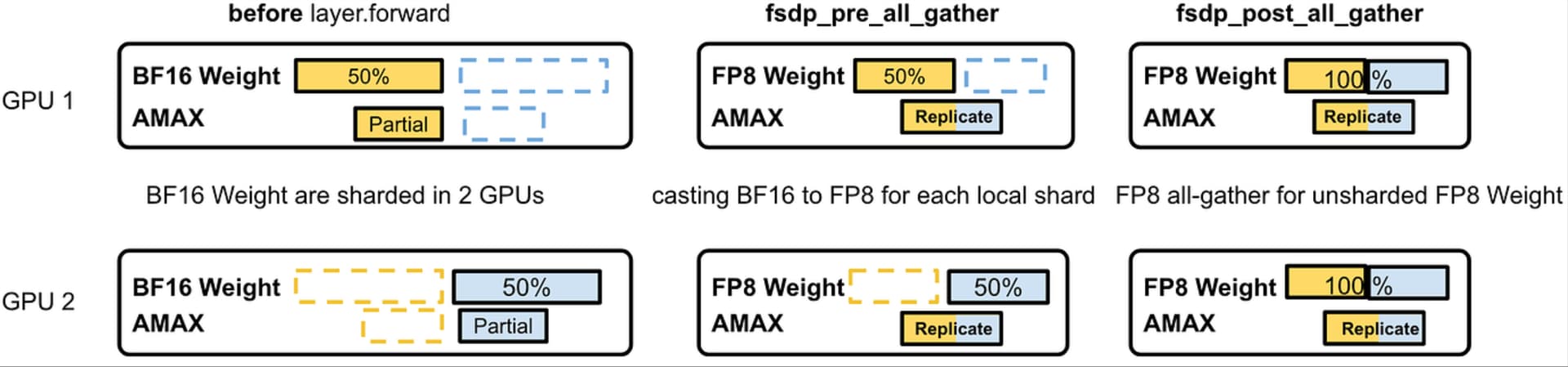
FSDP2 extensions for float8 tensor subclass: We keep FSDP2 UX the same across bfloat16 models and float8 models because we implemented the float8 casting in FSDP2 extensions. The float8 linear module’s weight is a tensor subclass that knows how to cast to float8. We can customize the casting logic before and after all-gather, as shown by the following figure.
- fsdp_pre_all_gather (code): casting the bfloat16 weight into a float8 weight according to the latest replicated AMAX/scale (requiring all-reduce). Note the bfloat16 weight here is sharded by 1/NGPU. Since we all-reduce to get the replicated AMAX and scale on all ranks, casting the sharded bfloat16 parameters to float8 before all-gather is equivalent to all-gathering bfloat16 parameters and then casting to float8.
- fsdp_post_all_gather (code): constructing Float8Tensor from all-gathered float8 data and replicated scale so they are ready for float8 compute in forward and backward.
Deep Dive Into Performance
We discuss key optimizations in float8 to reach 1.50x speed up vs bfloat16.
Float8 Compute + Bfloat16 All-Gather (1.40x speed up, code): When swapping nn.Linear with Float8Linear, it’s possible to keep the bfloat16 weight as is. We simply treat Float8Linear like a normal nn.Linear and perform bfloat16 all-gather in FSDP2 (stream 22). Float8Linear.forward is responsible for both bfloat16-to-float8 casting and float8 matmul (stream 7). This approach achieved 1.40x speed up and is a strong baseline to showcase the importance of float8 compute. However, it wasted 50% bandwidth to communicate bfloat16 parameters while those parameters will eventually get casted to float8 during forward.

Float8 All-Gather with Individual AMAX All-Reduce (+0.02x on top of 1.40x, code ): We perform float8 casting before all-gather to save 50% bandwidth (stream 22). As a result, Float8Linear.forward uses float8 weights directly without the need for casting (stream 7). However, float8 casting requires a global AMAX (argmax of abs(max)) so we need to all-reduce partial AMAX (a scalar) across N ranks (stream 22 and 35). Each float8 parameter requires 1 all-reduce. Those small all-reduces degraded overall performance.

Combined AMAX AllReduce (+0.08x on top of 1.42x, code ): We perform single all-reduce for all float8 parameters after the optimizer step. As a result, we avoided small all-reduces inside FSDP hooks (stream 47). We achieved horizontal fusion by calculating AMAX for all float8 parameters at once.

SM contention between NCCL and Float8 compute : Depending on NCCL version and GPU total SMs, sometimes there are bubbles in float8 compute (stream 7). Both float8 compute (sm90_xmm ) and float8 all-gather (ncclDevKernel ) fight for SMs. The ideal case is to always prioritize float8 compute for layer k over float8 all-gather for layer k+1. In that case, if NCCL uses less SMs for slower communication or float8 compute uses less SMs. We find it useful to set NCCL_MAX_CTAS ) to 16 or 8 during benchmarking to resolve contention.

Future Work
We are actively exploring the following directions (see more in PyTorch roadmap )
Float8 in tensor parallel and pipeline parallel: for tensor parallel (including sequence parallel), we shard module input along sequence dim and would need float8 all-gather for inputs. For pipeline parallel, we are verifying if there are any performance gaps for float8.
Delayed scaling: Comparing to dynamic scaling, delayed scaling gains perf by deriving AMAX from previous iterations. The cost is potential loss of numerical accuracy. In practice, float8 weights remain stable within adjacent iterations. We want to support delayed scaling to reach full performance.
Row-wise scaling: Compared to tensor-wise scaling, row-wise scaling preserves better numerical accuracy by having fine-grained scales for each row. The cost is the complexity in the backward, because matrices are transposed from row-wise to column-wise. It requires special treatment for float8 all-gather in FSDP2. This is still a highly exploratory direction.