with Horace He, Less Wright, Luca Wehrstedt, Tianyu Liu, Wanchao Liang
TL;DR
- We implemented experimental async tensor parallelism support in PyTorch.
- We integrated it in TorchTitan and observed:
- Up to ~29% forward pass speedup and ~8% E2E speedup in Llama3 7B.
- Up to ~20% forward pass speedup and ~8% E2E speedup in Llama3 70B.
- We briefly discuss the performance challenges and the solutions we devised.
Distributed with TorchTitan
The GitHub repository torchtitan is a proof of concept for large-scale LLM training using native PyTorch, designed to be easy to understand, use, and extend for different training purposes, supporting multi-dimensional parallelisms with modular components. In this series of topics, we introduce the latest PyTorch features for distributed training enabled in TorchTitan.
- Topic 1: Enabling Float8 All-Gather in FSDP2
- → Topic 2: Introducing Async Tensor Parallelism in PyTorch
Tensor Parallelism
Tensor parallelism (TP) is a widely used model parallelism technique. Unlike data parallelism, which is limited to sharding computations across the batch dimension, TP further distributes the computation along the feature dimension, allowing multiple GPUs to process the same sample simultaneously. This characteristic makes TP crucial for large-scale LLM training, allowing the number of devices to scale beyond the global batch size.
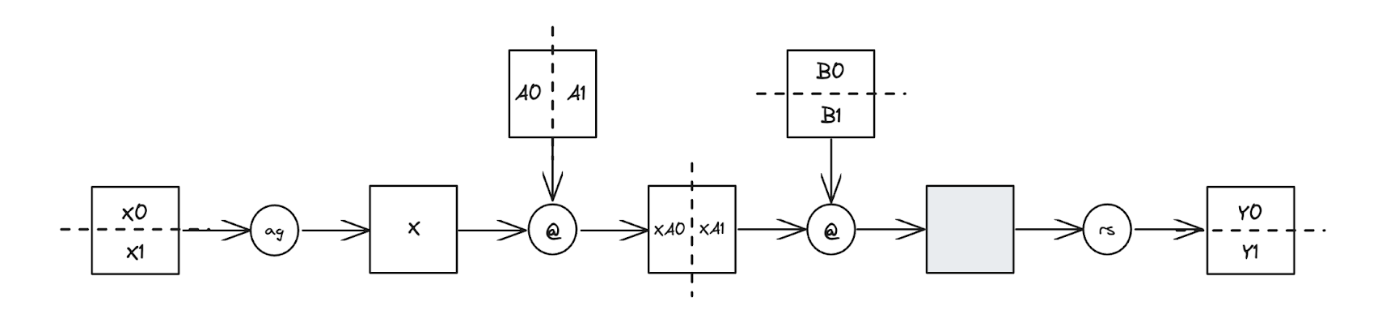
Figure 1: TP applied to a two-layer FFN sharded across 2 devices
As a brief recap, the diagram illustrates TP applied to a two-layer FFN sharded across 2 devices. We begin with row-wise sharded inputs [X0, X1], column-wise sharded linear weights [A0, A1], and row-wise sharded linear weights [B0, B1]. First, an all-gather is performed on [X0, X1] to produce the unsharded input X. Then, X @ A0 @ B0 and X @ A1 @ B1 are computed independently on each device, with activations remaining sharded. The resulting partial sums of the unsharded output are then combined using a reduce-scatter to form the final sharded output.
This approach efficiently minimizes communication volume by keeping the activations sharded as long as possible. However, the communication still poses efficiency challenges because it is exposed. Async tensor parallelism is an optimization designed to address this issue.
Async Tensor Parallelism
The concept of async tensor parallelism (async-TP [1] was, to our knowledge, first introduced in the paper Breaking the Computation and Communication Abstraction Barrier in Distributed Machine Learning Workloads, although there have been several parallel efforts, including Wang et al. 2022. and Chang et al. 2024. The key insight is that by decomposing dependent communication and computation operators, we can create overlapping opportunities that would otherwise be unachievable.
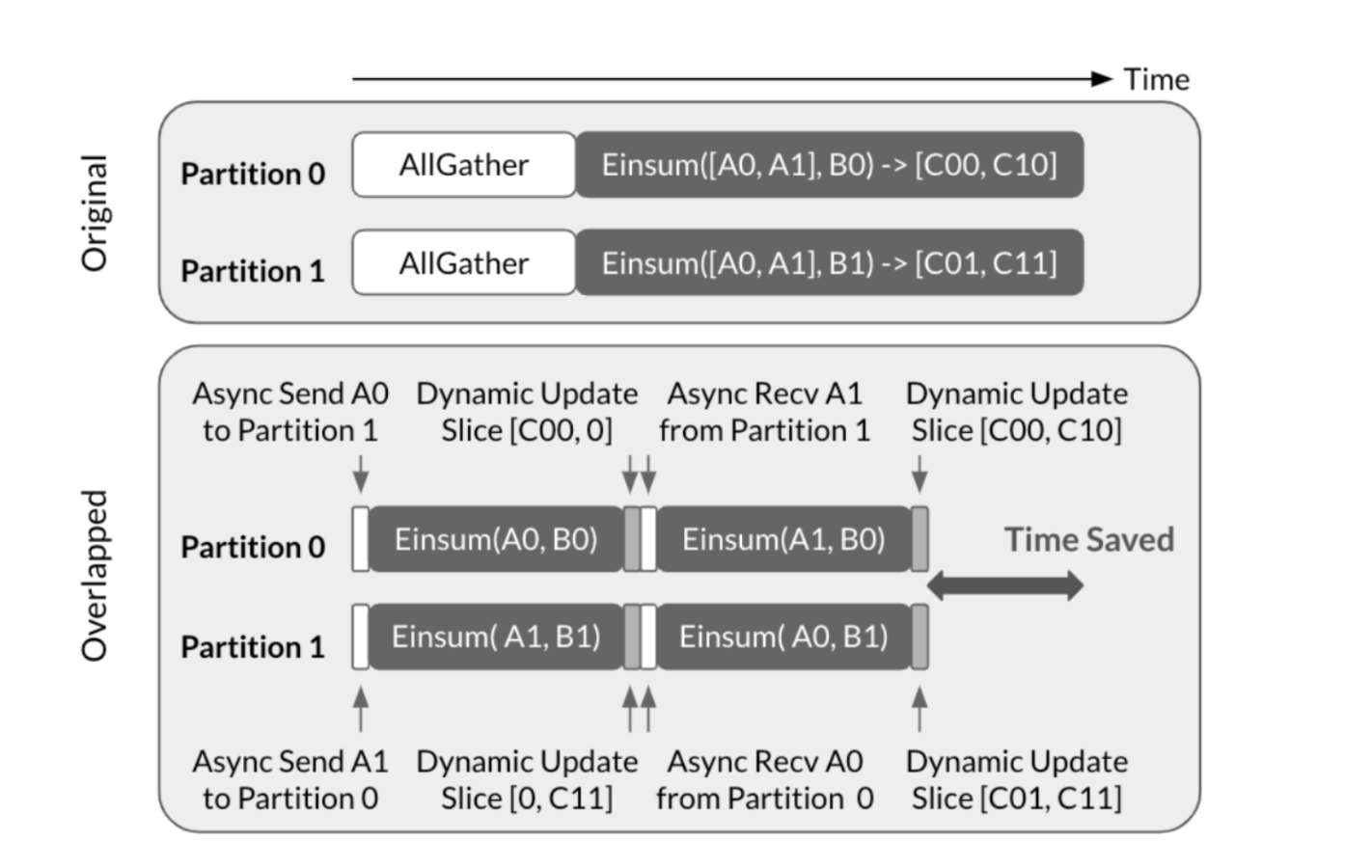
Figure 2: Async-TP applied to an all-gather followed by a matmul
The diagram from Wang et al. illustrates how this technique can be applied to an all-gather followed by a matmul. The all-gather is decomposed into send and recv operations, while the matmul is divided into sub-matmuls. With this decomposition, it becomes possible to compute one sub-matmul while simultaneously transfering the data required for the next sub-matmul, effectively hiding communication latency.
Performance Challenges
Although the concept of async-TP is straightforward in theory, achieving a performant CUDA implementation presented several challenges. In this section, we’ll explore these challenges and discuss the approaches we employed to address them.
Acknowledgment: Many of these challenges were initially explored by Luca Wehrstedt. The async-TP implementation in PyTorch drew significant inspiration from his async-TP work in xformers.
Communication Overhead
When decomposing communication, it might be tempting to use NCCL send/recv due to their accessibility. However, NCCL send/recv has certain characteristics that make them less ideal for async-TP:
-
Contention between overlapped computation and communication - while it’s commonly believed that computation and communication are two resources that can be utilized independently, in reality, their independence is nuanced, and contention does occur. In intra-node settings (most common for TP), NCCL send/recv kernels utilize SMs to move data across NVLink, reducing the number of SMs available for the overlapping matmul kernels and slows them down. Interestingly, the observed slowdown can exceed the percentage of resources consumed by the communication kernels. Since cuBLAS attempts to select kernels that execute in full waves, the SMs taken by the communication kernel can tip the balance, causing the matmul kernels to execute an extra wave.
-
Two-way synchronization - NCCL send/recv kernels perform two-sided synchronization, meaning that both the sender and receiver are blocked until the operation is complete. This approach is not always optimal for data transfers within intra-op parallelism. Depending on the scenario, it may be preferable to perform a single synchronization for multiple data transfers or to choose between pushing data to or pulling data from remote peers.
Fortunately, we can avoid the previously mentioned downsides by leveraging CUDA’s P2P mechanism. The mechanism allows a device to access memory allocated on a peer device by mapping it into its virtual memory address space. This mechanism enables memory operations (load/store/atomic, etc.) to be executed over NVLink [2]. Moreover, when transferring contiguous data to or from peer devices via cudaMemcpyAsync, the operation is handled by copy engines [3] and does not require any SMs, thereby avoiding the contention issues discussed earlier [4].
To leverage this mechanism for async-TP and similar use cases in the future, we developed an experimental abstraction called SymmetricMemory. It conceptually represents a buffer symmetrically allocated across a group of devices, providing each GPU with access to all corresponding buffers on its peers via virtual memory/multicast addresses. Direct interaction with SymmetricMemory is not necessary for using async-TP, but users can leverage it to create custom fine-grained, intra-node/intra-op optimizations similar to async-TP.
Magnified Wave Quantization Inefficiency Due to Work Decomposition
Tiled matmul kernels execute in waves of SM count. If the final wave consists of only a few tiles, it will take nearly as long to complete as a full wave, leading to what is known as quantization inefficiency. Decomposing a matmul leads to a smaller number of tiles per kernel [5] and the combined quantization inefficiency from the decomposed matmuls is likely to exceed that of the original matmul.
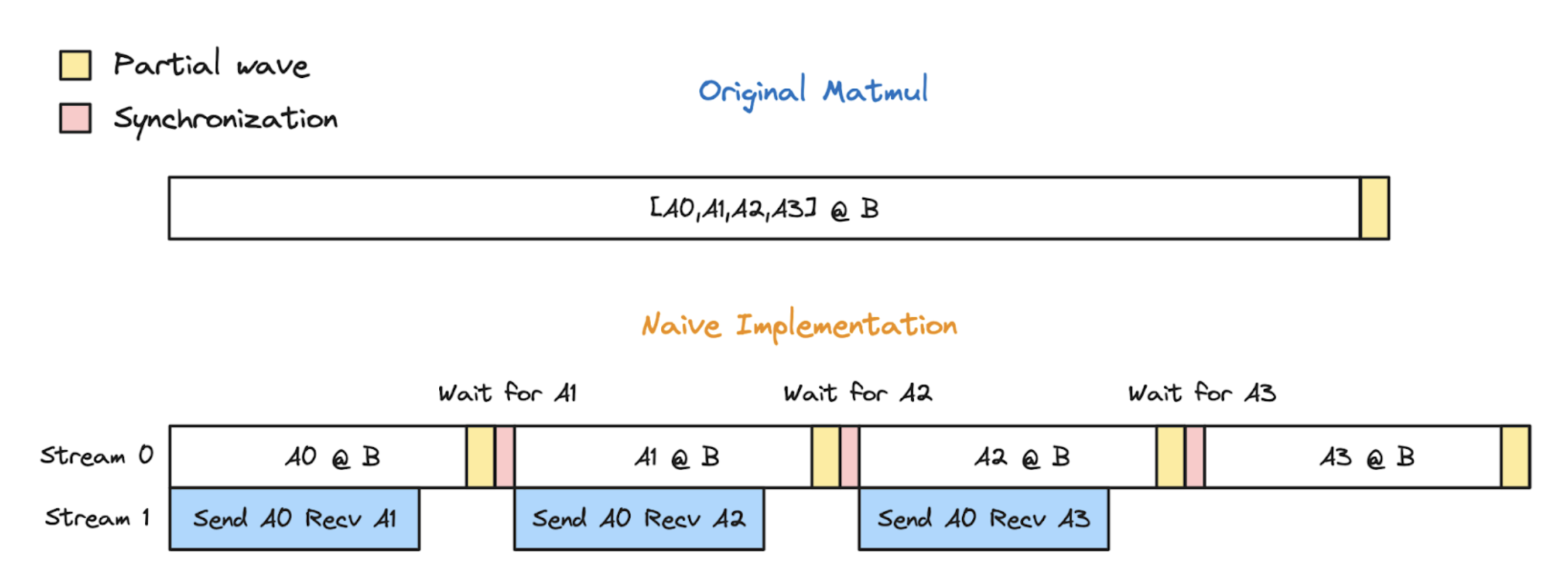
Figure 3: Decomposing a matmul leads to magnified quantization inefficiency
To illustrate the issue, let’s examine an all-gather → matmul example. In this example, A is sharded across 4 devices. Without async-TP, A is first all-gathered from the 4 devices, and then A @ B is computed on all devices. With async-TP, A @ B is decomposed into A0 @ B, A1 @ B, A2 @ B, and A3 @ B. An native async-TP implementation would execute the sub-matmuls sequentially in one stream while prefetching the data required for the next sub-matmul on another stream. This approach effectively hides communication latency. However, because the matmul is decomposed into smaller parts, the number of partial waves increases, leading to a longer overall matmul execution time.
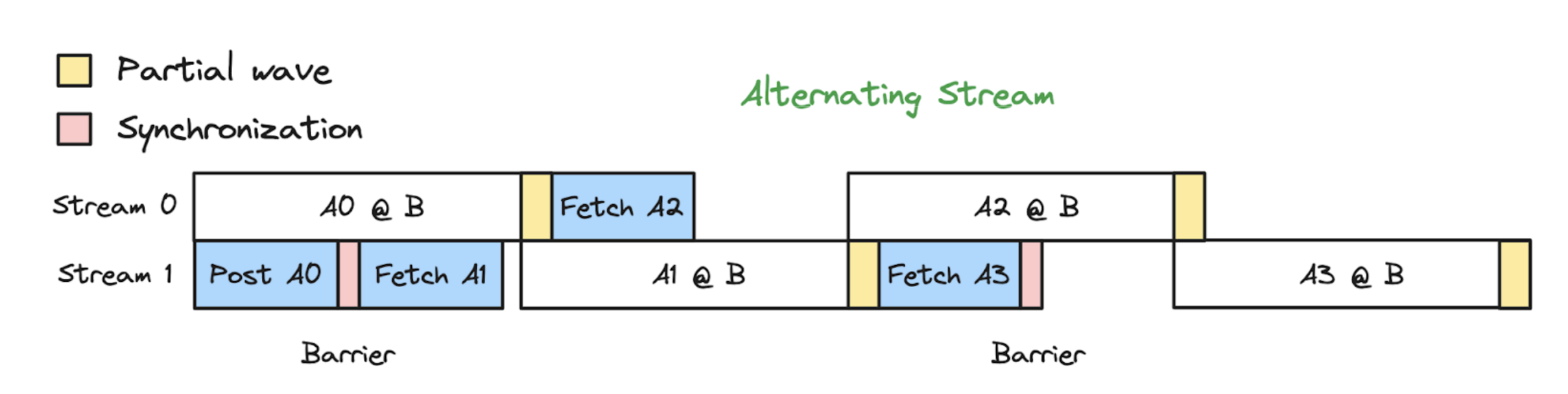
Figure 4: The alternating-stream implementation allows partial waves to overlap with the next sub-matmul
To combat the magnified quantization inefficiency, we adopted an alternating-stream approach. Instead of using dedicated streams for computation and communication, we employ two symmetric streams that alternate roles. This method not only allows us to overlap computation with communication but also enables overlapping the partial wave of the current sub-matmul with the next sub-matmul, thereby mitigating the additional quantization inefficiency caused by decomposition.
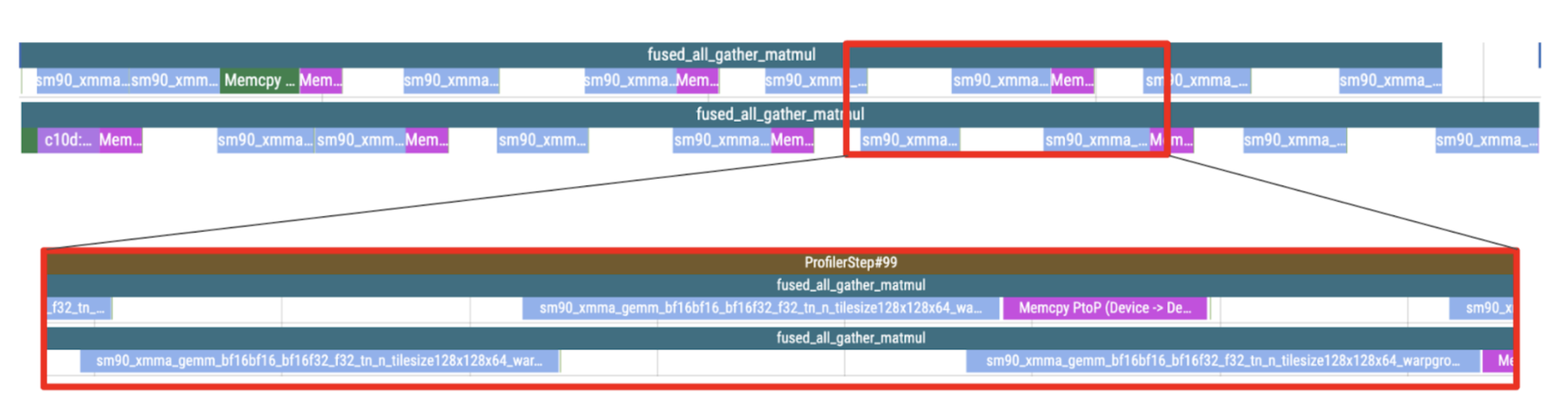
Figure 5: Profiling trace of partial waves overlapping with the next sub-matmul
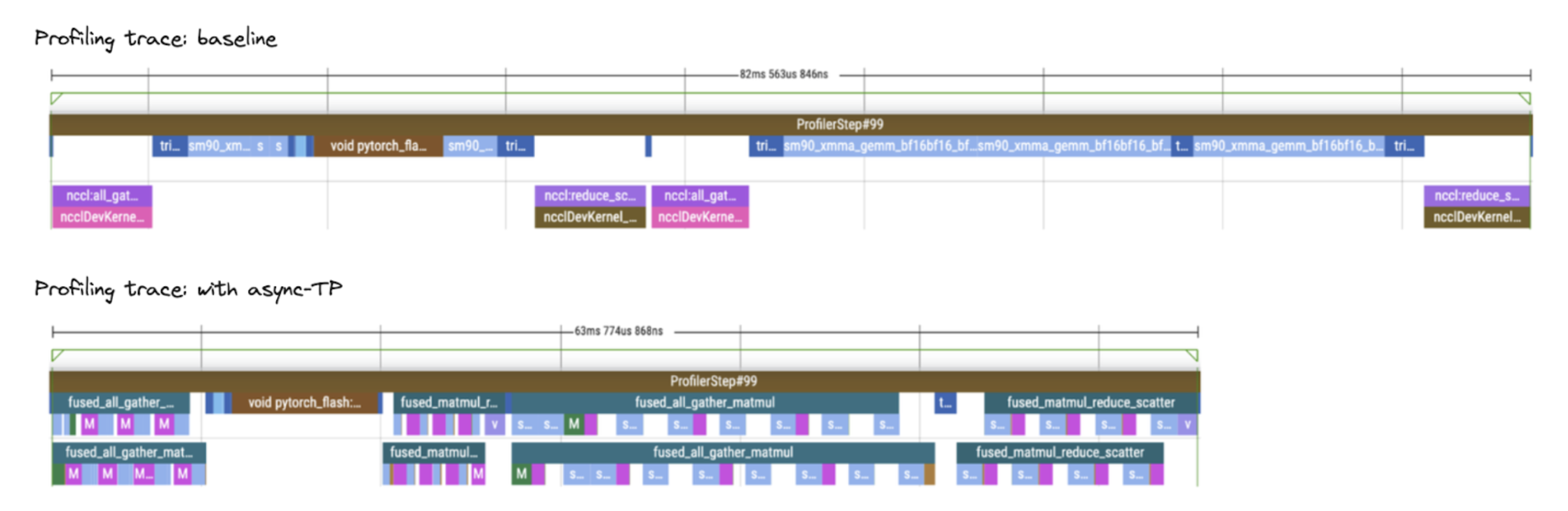
Figure 6: Profiling trace comparison between baseline and async-TP
E2E Performance Evaluation
We conducted an E2E performance evaluation on Llama3 8B and 70B with TorchTitan. We observed up to ~29% forward pass speedup and ~8% E2E speedup in Llama3 8B, and up to ~20% forward pass speedup and ~8% E2E speedup in Llama3 70B.
Benchmark configuration:
- The benchmarks were conducted with 64 H100 GPUs [6], each host equipped with 8 GPUs and NVSwitch.
- torch.compile was enabled for both the baseline and async-TP configurations.
- The models were trained using bf16 precision.
- We applied selective activation checkpointing for Llama3 8B and full activation checkpointing for Llama3 70B.
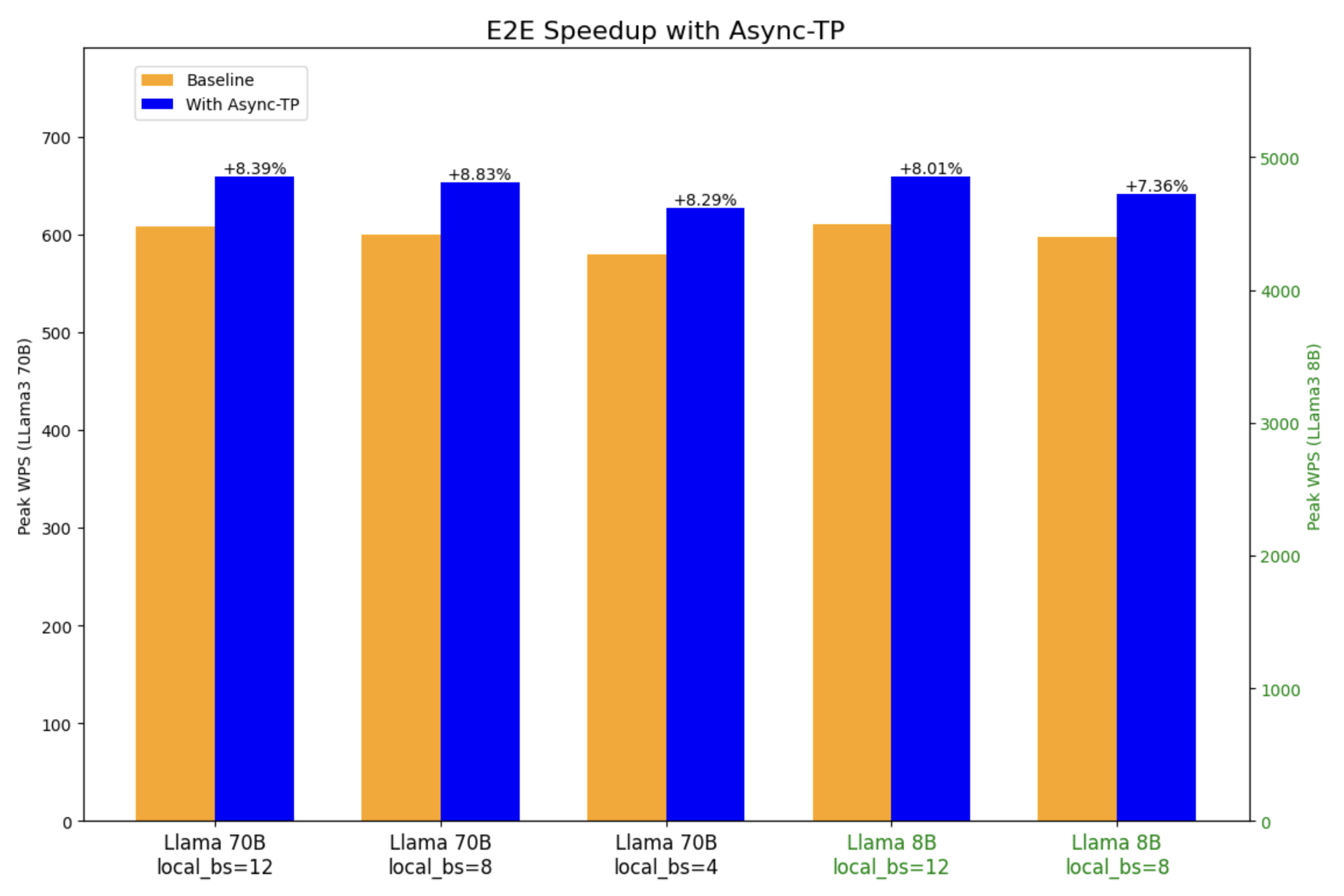
Figure 7: E2E speedup with async-TP
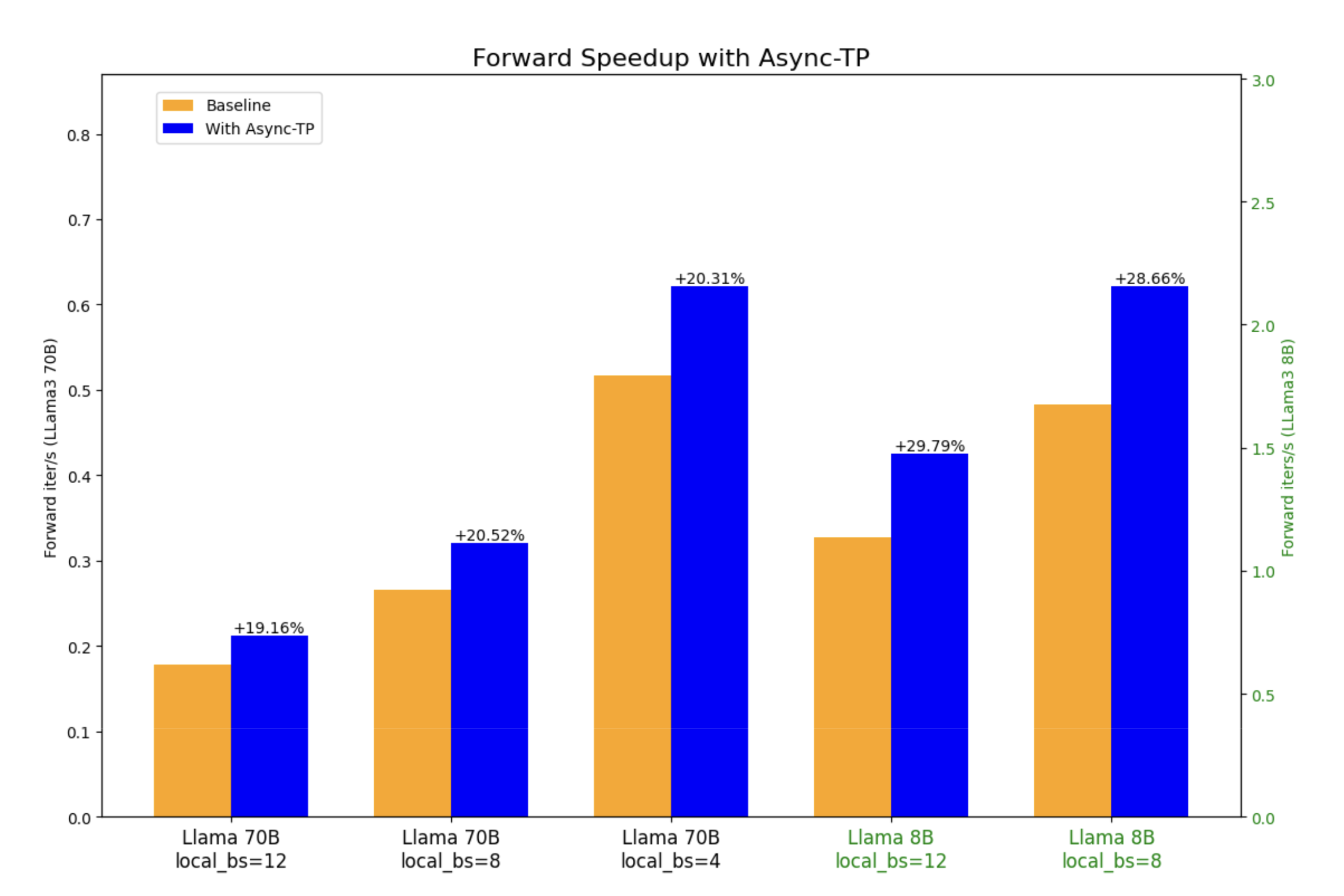
Figure 8: Forward speedup with async-TP
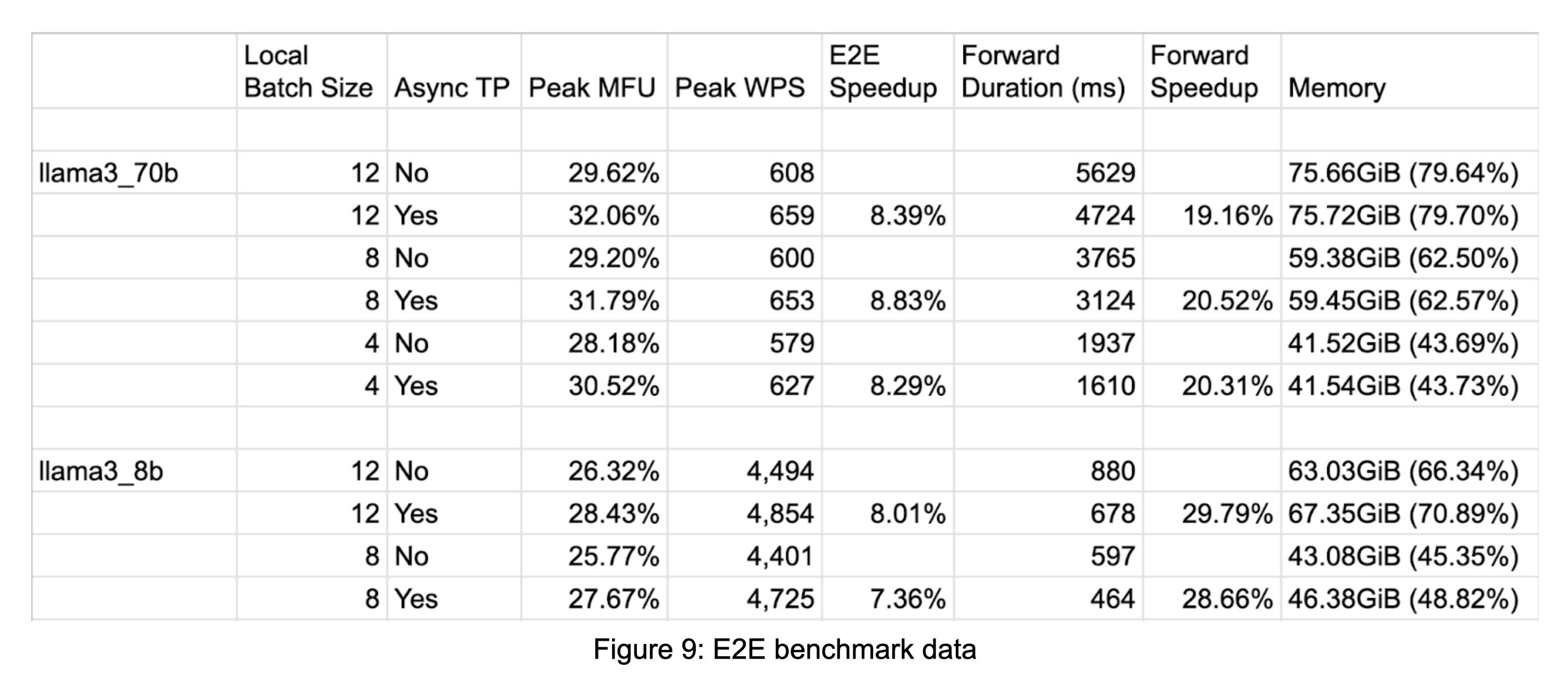
Figure 9: E2E benchmark data
We also conducted benchmarks with async-TP on Llama 3.1 405B. You can find the details here.
Using Async-TP in TorchTitan
The async-TP support is readily integrated into TorchTitan. To enable it, simply supply the --experimental.enable_async_tensor_parallel option when training with tensor parallelism.
Using Async-TP in PyTorch
The async-TP support is available in the latest PyTorch nightly builds. You can use it either with torch.compile or directly in eager mode.
Using Async-TP with torch.compile:
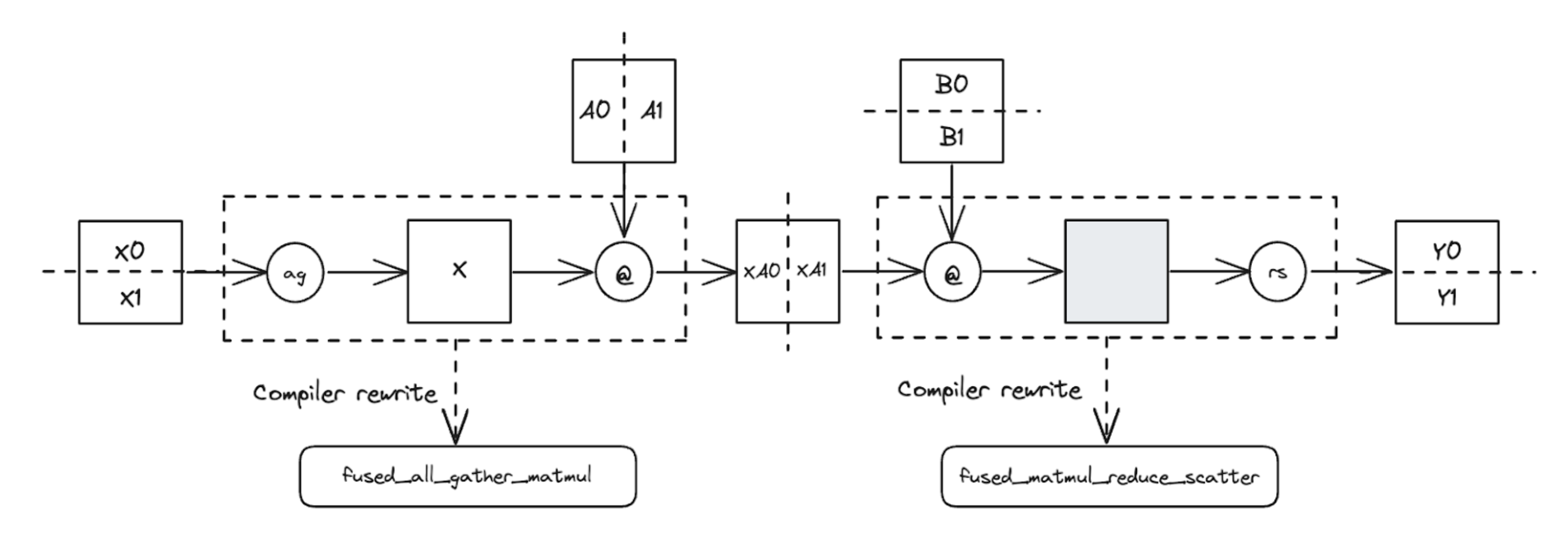
Figure 10: torch.compile automatically detects TP patterns and rewrites them into async-TP ops
torch.compile is currently our recommended method for applying async-TP:
- It automatically detects TP patterns in your model and rewrites them into async-TP ops, allowing your model to maintain its original structure.
- The optimized async-TP implementation requires the inputs to be in a specific layout; otherwise extra copies will occur. torch.compile automatically ensures that upstream ops produce outputs in the desired layout whenever possible.
- torch.compile is also capable of detecting situations where an all-gather can be overlapped with multiple matmuls, potentially better hiding communication latency.
While these can be achieved manually in eager mode, they may introduce tighter coupling between model code and optimization logic.
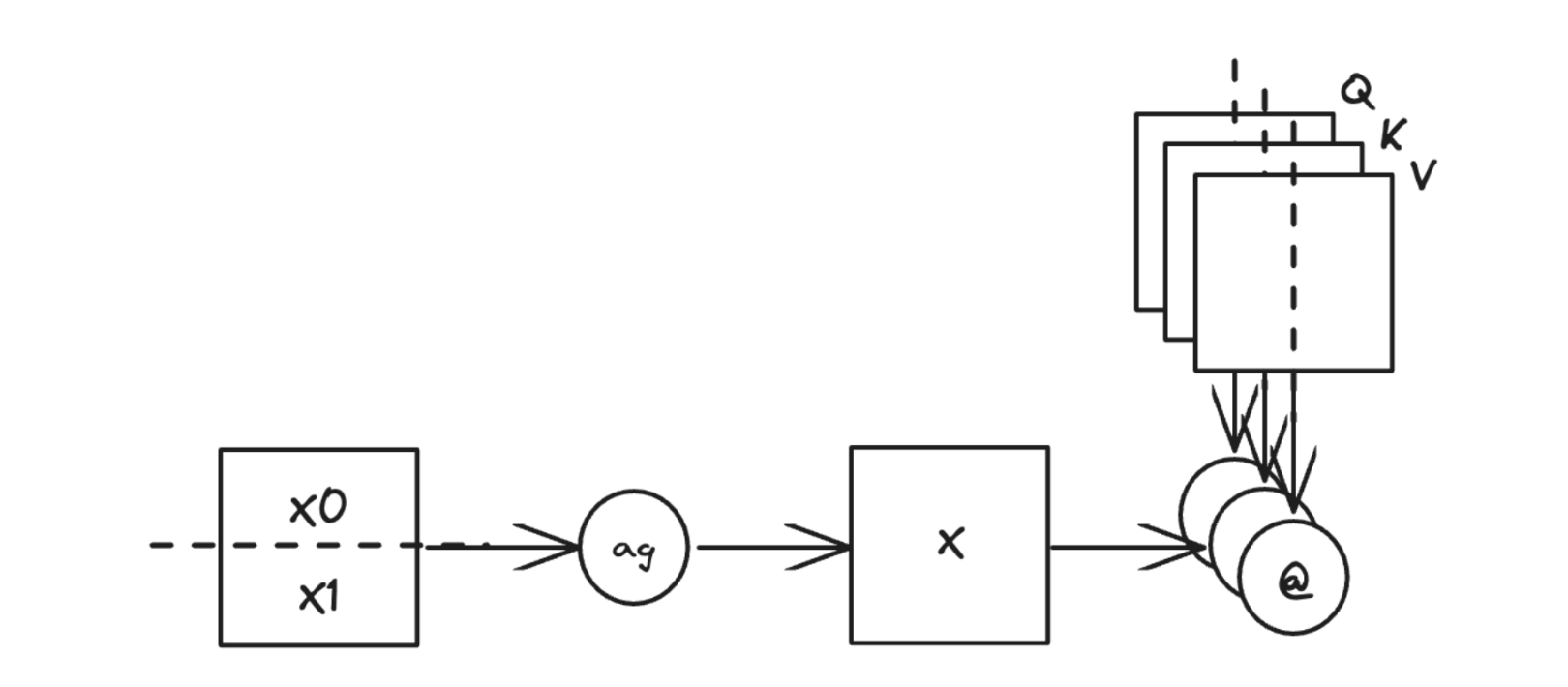
Figure 11: torch.compile can automatically apply async-TP to an all-gather followed by multiple matmuls that consume the all-gather result (e.g., QKV projection)
For authoring TP logic, we recommend PyTorch Tensor Parallel APIs. You can find the tutorial here and an example in TorchTitan here. Additionally, torch.compile can apply async-TP to TP logic that is manually authored using functional collectives along with torch.mm, torch.matmul, or torch._scaled_mm. An example can be found here.
from torch.distributed._symmetric_memory import enable_symm_mem_for_group
# Enable symmetric memory for the TP process group
enable_symm_mem_for_group(tp_group.group_name)
# Tell torch.compile to enable async-TP
torch._inductor.config._micro_pipeline_tp = True
# Apply torch.compile to the model
model = torch.compile(model)
# Or apply torch.compile to only the model region that contains TP logic
model.tp_submodule = torch.compile(model.tp_submodule)
Using Async-TP in eager mode:
It is also possible to apply async-TP in eager mode by directly calling async-TP ops:
from torch.distributed._symmetric_memory import enable_symm_mem_for_group
# Enable symmetric memory for the TP process group
enable_symm_mem_for_group(tp_group.group_name)
# Invoke the async-TP operators directly
# all-gather -> matmul
ag_output, mm_outputs = torch.ops.symm_mem.fused_all_gather_matmul(
x,
[wq, wk, wv],
gather_dim=1,
group_name=tp_group.group_name,
)
# matmul -> reduce-scatter
output = torch.ops.symm_mem.fused_matmul_reduce_scatter(
x,
w,
"avg",
scatter_dim=0,
group_name=tp_group.group_name,
)
Limitations and Future Work
Current limitations of the async-TP support in PyTorch:
- Optimized for large matmul problems: Currently, async-TP in PyTorch performs best with large matmul operations, particularly those that don’t require changes in tiling size after decomposition. We are exploring finer-grained pipeline solutions to enhance performance on smaller problem sizes, such as those encountered in inference workloads.
- Requires NVSwitch: At present, async-TP in PyTorch relies on NVSwitch for optimal performance. We are considering extending support to NVLink ring topologies based on community feedback and demand.
- Limited to intra-node configurations: async-TP in PyTorch currently only works for intra-node setups. We may explore extending this support to cross-node environments in the future.
Notes
[1]: PyTorch Distributed opted the term “async-TP” to describe this technique, but it may not be universally referred to by this name.
[2]: Currently, the async-TP implementation in PyTorch requires an NVLink connection between all device pairs (e.g., through NVSwitch) to achieve speedup. This is a limitation that we plan to address in future.
[3]: Copy engines are dedicated hardware units on a GPU that manage data movement between different memory locations and operate independently of the GPU’s computational cores (SMs).
[4]: Data transfers via copy engines still share the same memory bandwidth. However, this is unlikely to cause significant contention because (1) the transfer rate is limited by NVLink bandwidth, which is low enough to avoid memory bandwidth contention, and (2) the overlapped matmul is compute-bound.
[5]: We assume that the matmul problem size is large enough, so that the tile shape doesn’t change after decomposition and the main source of decomposition overhead is quantization inefficiency.
[6]: The H100 GPUs used for the benchmark were non-standard. They have HBM2e and are limited to a lower TDP. The actual peak TFLOPs should be between SXM and NVL, and we don’t know the exact value. So the reported MFU is lower than the actual MFU because we use the peak TFLOPs of SXM directly.