with Lucas Pasqualin, Iris Zhang, Less Wright, Pradeep Fernando, Will Constable
TLDR
- We integrated PyTorch Distributed Checkpointing (DCP) into TorchTitan, enabling efficient distributed checkpointing.
- We implemented asynchronous checkpointing within PyTorch’s DCP, allowing storage operations to overlap with subsequent training iterations, thereby optimizing process efficiency.
- This resulted in a 19X reduction in checkpoint overhead compared to synchronous checkpointing.
- We developed a prototype of zero-overhead checkpointing using DCP in TorchTitan, which further overlaps the GPU to CPU copy with subsequent forward and backward operations.
- This approach achieved an additional 5X reduction in checkpoint overhead compared to asynchronous checkpointing, bringing the total checkpoint overhead to under one second.
Distributed with TorchTitan
The GitHub repository TorchTitan is a proof of concept for large-scale LLM training using native PyTorch, designed to be easy to understand, use, and extend for different training purposes, supporting multi-dimensional parallelisms with modular components. In this series of topics, we introduce the latest PyTorch features for distributed training enabled in Torchtitan.
- Topic 1: Enabling Float8 All-Gather in FSDP2
- Topic 2: Introducing Async Tensor Parallelism in PyTorch
- → Topic 3: Optimizing Checkpointing Efficiency with PyTorch DCP
Introduction to DCP
Checkpoints are crucial in training large models, serving two primary purposes: they can be retrieved for applications such as inference and evaluation, and they can be used to recover from failures. Effective checkpointing should ensure that checkpoints are easily reusable and do not become performance bottlenecks. This section explores how PyTorch Distributed Checkpoint (DCP) meets these objectives.
There are two common distributed checkpointing methods. The first involves gathering all model weights and optimizer states to a single rank, typically rank 0, which then saves the full checkpoint. While straightforward, this method is slow and inefficient in terms of storage I/O utilization, as it only uses rank 0’s storage I/O and involves extra communication that can pose performance issues. The second method allows each rank to save its local states independently, speeding up the process by utilizing all available I/O resources. However, this often requires cumbersome and non-scalable post-processing with proprietary parallelism information to adapt the sharded checkpoints for different uses.
To address these challenges, we introduced DCP in PyTorch. DCP enables each rank to save its tensors locally without the need for communication of tensors, while retaining the information necessary to later reassemble the checkpoint for various parallelisms or into a complete checkpoint. DCP’s design is parallelism-agnostic, relying solely on DTensors produced by PyTorch’s native distributed parallelisms (e.g., DDP, FSDP2, TP, PP). It analyzes and converts DTensors (or torch.Tensors) to an internal format without requiring knowledge of the underlying parallelisms.
When loading a checkpoint, DCP uses the current state dictionary to determine the tensor sharding, fetching data on-the-fly. Users can also opt to preprocess the checkpoint offline to minimize loading times. DCP simplifies post-processing by converting the internal format to the final result.
The figure illustrates the saving flow. In this example, parameter P2 is sharded across rank0 and rank1, while parameter P1 remains unsharded on rank0. When saving the state_dict on each rank, no communication occurs for the tensor data itself. However, there is communication related to the metadata, which is then saved in a metadata file. This metadata file details the offset and length of each parameter in the respective files. Please note that the figure is intended for explanatory purposes and simplifies some aspects; actual implementation details may vary.

Integrating DCP into TorchTitan
To utilize DCP for saving checkpoints in TorchTitan, the following code snippet can be used:
import torch.distributed.checkpoint as dcp
def save_checkpoint(self, state_dict: Dict[str, Any], path: Union[str, os.PathLike]):
dcp.save(state_dict, path)
The path argument can be a regular path to a local file system or a path to storage supported by fsspec. For those who wish to use their own proprietary storage solutions, DCP also allows for customization of the storage backend. The state_dict argument is a dictionary containing the states to be saved. DCP iterates through state_dict, checking if each value has a state_dict() method. If so, DCP calls this method on the object and saves the returned value. Otherwise, it directly saves the values. To save both a model and its optimizer, the following state_dict would be sufficient:
model = MyModel()
optim = MyOptimizer(model)
state_dict = {"model": model, "optimizer": optim}
However, this state_dict content is suitable for models parallelized using data parallelism and tensor parallelism but not for pipeline parallelism. Also, it cannot be used to reshard the optimizer across a different number of GPUs or different parallelisms. Both limitations arise because torch.optim.Optimizer.state_dict() returns a dictionary using parameter IDs to represent parameters/states, rather than fully qualified names (FQN). Unlike model.state_dict(), which returns keys like layer1.weight (a unique FQN regardless of GPU distribution or model parallelization), optim.state_dict() represents layer1.weight with a numerical ID that reflects the order in which the parameter was passed into the optimizer. This parameter ID is not unique and can lead to conflicts, especially under pipeline parallelism where parameters like layer1.weight and layer2.weight might end up on different GPUs with the same parameter ID.
To address this issue, we implemented distributed state_dict APIs in PyTorch, which convert both model and optimizer state_dict to be distributed-checkpoint-friendly. In TorchTitan, we use the following OptimizerWrapper to encapsulate the optimizer (we will omit the discussion of ModelWrapper as its fundamental concept is identical to that of OptimizerWrapper.):
class OptimizerWrapper(Stateful):
def __init__(
self,
model: Union[nn.Module, List[nn.Module]],
optim: Union[torch.optim.Optimizer, List[torch.optim.Optimizer]],
) -> None:
self.model = [model] if isinstance(model, nn.Module) else model
self.optim = [optim] if isinstance(optim, torch.optim.Optimizer) else optim
def state_dict(self) -> None:
func = functools.partial(
get_optimizer_state_dict,
options=StateDictOptions(flatten_optimizer_state_dict=True),
)
return {k: v for sd in map(func, self.model, self.optim) for k, v in sd.items()}
def load_state_dict(self, state_dict: Dict[str, Any]) -> None:
func = functools.partial(
set_optimizer_state_dict,
optim_state_dict=state_dict,
options=StateDictOptions(flatten_optimizer_state_dict=True),
)
list(map(func, self.model, self.optim))
Instead of directly passing the model and optimizer to dcp.save(), TorchTitan uses model_wrapper and optim_wrapper. Notably, OptimizerWrapper (and similarly, ModelWrapper) can accept lists of models and optimizers, accommodating some pipeline parallelism algorithms that manage multiple model and optimizer chunks per rank. The distributed state_dict can flatten multiple state_dict entries into one.
This section outlines the basic concept of integrating DCP into TorchTitan. For more detailed information, please refer to the code.
Asynchronous Checkpointing
While using DCP avoids the need to aggregate tensors, the checkpointing overhead remains substantial compared to the training step. During checkpointing, the trainer must wait for the process to complete, effectively wasting GPU resources.
Checkpointing faces two major bottlenecks: copying tensors from GPU to CPU memory (referred to as “staging”) and transferring tensors from CPU memory to persistent storage, as illustrated in the figure below. The figure depicts three different tasks (training, staging and persistence step) along the time axis (x-axis), requiring the trainer to pause training and switch to perform staging and then the persistence step. Staging overhead for modern models typically lasts a few seconds, while the persistence step can take anywhere from tens to hundreds of seconds, depending on the storage system.

A common method to mitigate this overhead is to reduce the frequency of checkpointing. For example, if the checkpointing overhead is 50 seconds and the goal is to limit GPU time wastage to no more than 1%, the optimal solution would be to save a checkpoint every 5000 seconds. While this frequency might be acceptable on a smaller scale, it becomes problematic when training across hundreds or thousands of GPU nodes. At such a large scale, assuming no node failures within 5000 seconds is unrealistic. A single node failure within this period would require all nodes to restart from the last checkpoint due to the SPMD nature of the training, significantly reducing training efficiency.
To address this inefficiency, we implemented asynchronous checkpointing in DCP. The fundamental principle of asynchronous checkpointing is that the persistence step, which does not involve GPUs, can run concurrently with the training step on a separate thread. With asynchronous checkpointing, the process begins with the main training pausing to copy tensors from GPU to CPU memory. After this, the main training thread resumes the training task, while the persistence step is delegated to another thread. The figure below illustrates the concept of asynchronous checkpointing. Instead of the main thread handling the persistence step, it simply launches another thread dedicated to this task and immediately returns to the training.

The figure below displays the experimental results. We trained the Llama 3 8B model using TorchTitan FSDP2 on 8 nodes equipped with 64 H100 GPUs. The checkpointing frequency was set to every 100 iterations. From the figure, it is apparent that training 100 iterations without checkpointing takes approximately 270 seconds. With synchronous checkpointing, the checkpoint overhead nearly reaches 50 seconds. Clearly, this overhead is too substantial to maintain a checkpointing frequency of every 100 iterations or every 5 minutes.

With asynchronous checkpointing, the checkpointing overhead is reduced to less than 0.5 seconds. Ideally, this would represent the total overhead for asynchronous checkpointing; however, due to the Python Global Interpreter Lock (GIL), the persistence thread occasionally impedes the main training thread, adding about 2.2 seconds of delay over the subsequent 10 training iterations. Despite the GIL issue, the results still show a significant improvement over synchronous checkpointing, with up to a 19X reduction in overhead. For this experiment, maintaining a checkpointing overhead limit of 1% allows us to feasibly increase the checkpoint frequency to every 5 minutes or every 100 iterations.
In addition to the experiment done with TorchTitan, we have collaborated with IBM to show the performance win of asynchronous checkpointing.
Zero-Overhead Checkpointing
Asynchronous checkpointing significantly reduces GPU waste, but even a 1% loss may be considered too high given the rising costs and power consumption of GPUs. Can we improve upon asynchronous checkpointing? What other factors still slow down the checkpointing?
One remaining bottleneck is the staging process—copying tensors from GPU to CPU memory. At first glance, it seems impossible to parallelize staging with training without risking partially updated states from the next training iteration that could result in incorrect checkpoints. However, a closer examination of a training step, which includes forward, backward, and optimization phases, reveals that only the optimization step modifies the states. Therefore, if we can overlap the staging with the forward and backward steps, we might nearly eliminate checkpointing overhead.
Indeed, this overlap is achievable by placing the staging process in a separate CUDA stream and setting all copy operations to non_blocking=True, only synchronizing the stream before the next optimization step. This strategy effectively conceals the staging process. We have implemented this in a PyTorch private API, _copy_state_dict, and utilized it in TorchTitan to prototype what we call zero-overhead checkpointing (or nearly zero-overhead).
However, if staging takes too long, it could still become visible if it exceeds the combined duration of the forward and backward steps. To enhance staging performance, we leverage CUDA’s option to allocate pinned memory, which speeds up the copy process.
Another challenge is preventing the staging thread from interfering with the main thread’s execution. In our prototype, we address this by creating a separate process for the persistence step. Although transferring tensors between processes can be time-consuming, PyTorch facilitates this with its ability to mark CPU tensors as shareable across processes. By combining pinned and shared memory features, we developed another PyTorch private API, _create_cpu_state_dict, which creates a CPU state_dict for staging in zero-overhead checkpointing.
The figure below illustrates the zero-overhead checkpointing flow. After initiating the staging within the staging CUDA stream context, the main thread can immediately resume training for iteration N + 1. The staging CUDA stream concurrently performs the staging process alongside the training. Before proceeding to the optimization step, the main thread must verify the status of the staging; this check incurs minimal overhead if the staging has already completed. Subsequently, the main thread can initiate the persistence step in a separate process, as previously discussed. The main thread then returns to the training task.
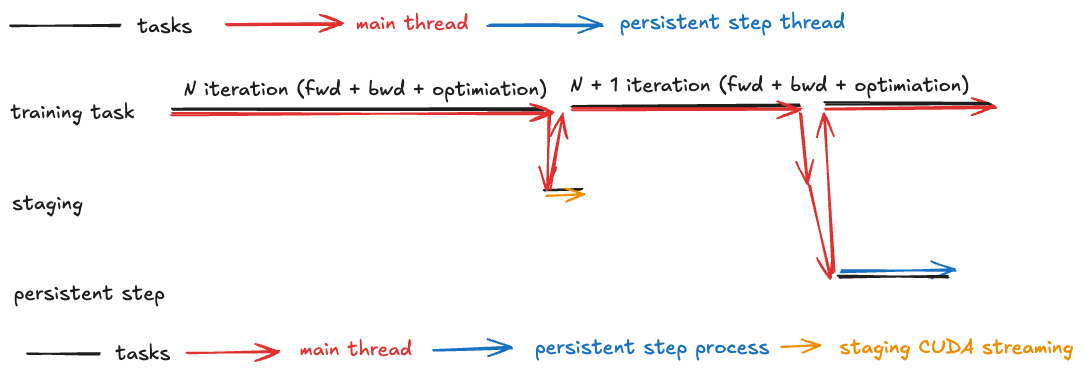
The figure below displays the experimental results using the same model and hardware configuration as described in the previous section. The results indicate that the staging overhead is merely 0.06 seconds, with subsequent training steps experiencing a slowdown of less than 0.4 seconds. This brings the total overhead to under 0.5 seconds—six times faster than asynchronous checkpointing. There is still room for improvement. The additional 0.35 seconds is primarily due to the main thread monitoring the staging CUDA stream status and transferring the state_dict to the persistence process. Future work could explore offloading these operations to another thread to further minimize overhead.

Compared to asynchronous checkpointing, zero-overhead checkpointing is more complex, requiring additional CPU memory (pinned memory is not pageable) and multiprocessing, which is more challenging to manage. Consequently, if CPU memory is constrained or if users prefer a simpler checkpointing process, asynchronous checkpointing might be a more suitable option. Despite these challenges, zero-overhead checkpointing represents a promising direction for enhancing training efficiency and GPU utilization.