with Howard Huang, Tristan Rice, Chien-Chin Huang
Summary
We recently integrated TorchFT into torchtitan and have added support for semi synchronous training on TorchTitan through the LocalSGD and DiLoCo algorithms. We wrapped the entire training loop in TorchTitan with an optional context manager to control the training method. In this post, we talk about the API and some of the changes we made. We also provide a visual demo and talk about future steps.
Distributed with TorchTitan Series
The GitHub repository torchtitan is a proof of concept for large-scale LLM training using native PyTorch, designed to be easy to understand, use, and extend for different training purposes, supporting multi-dimensional parallelisms with modular components. In this series of topics, we introduce the latest PyTorch features for distributed training enabled in Torchtitan.
- Topic 1: Enabling Float8 All-Gather in FSDP2
- Topic 2: Introducing Async Tensor Parallelism in PyTorch
- Topic 3: Optimizing Checkpointing Efficiency with PyTorch DCP
- Topic 4: Training with Zero-Bubble Pipeline Parallelism
- Topic 5: Breaking Barriers: Training Long Context LLMs with 1M Sequence Length in PyTorch Using Context Parallel
- → Topic 6: Semi synchronous training in combination using TorchFT
Background
TorchFT is a project aimed at providing per-step fault tolerance for PyTorch training jobs. It implements techniques that allow training to continue in the event of errors, without interrupting the entire process. TorchFT supports a range of distributed algorithms including DDP, HSDP, along with reusable components like coordination primitives and fault-tolerant ProcessGroup implementations.
Two popular semi-synchronous training algorithms are the LocalSGD and DiLoCo. These algorithms are termed “semi-synchronous” because they blend aspects of both asynchronous and synchronous training. In an asynchronous manner, workers compute gradients and update their parameters independently, without waiting for other workers. However, they also incorporate periodic synchronization, similar to fully synchronous methods, to ensure identical model parameters across all workers. The synchronization method differs for each algorithm:
LocalSGD: Synchronization is achieved by averaging each worker’s parameters.
DiLoCo: Synchronization involves averaging pseudogradients, which are the differences between the current model’s parameters and those from the last global update.
Given synchronization every N steps, when performing T training steps, each with C communication time, this would cut the total communication from TC to TC/N compared to fully synchronous methods. Because N is a hyperparameter, the staleness of the weights upon synchronization may affect convergence, so total training time is not calculated so cleanly and is an open area of research.
LocalSGD / DiLoCo API
We implemented LocalSGD and DiLoCo as context managers in TorchFT. In doing so, we don’t require any model changes or wrapping of the model which would affect the parameter FQNs, however we do need to make changes to the training loop in order to use these algorithms.
with semi_sync_training(
manager=ft_manager,
model=model
optimizer=optimizer,
sync_every=40
):
# training loop...
The context managers require the model’s optimizer that is used in training because it attaches optimizer hooks and fires whenever opt.step() is called to record the steps taken so far. Under the hood at every step, we also perform quorum by querying the lighthouse server.
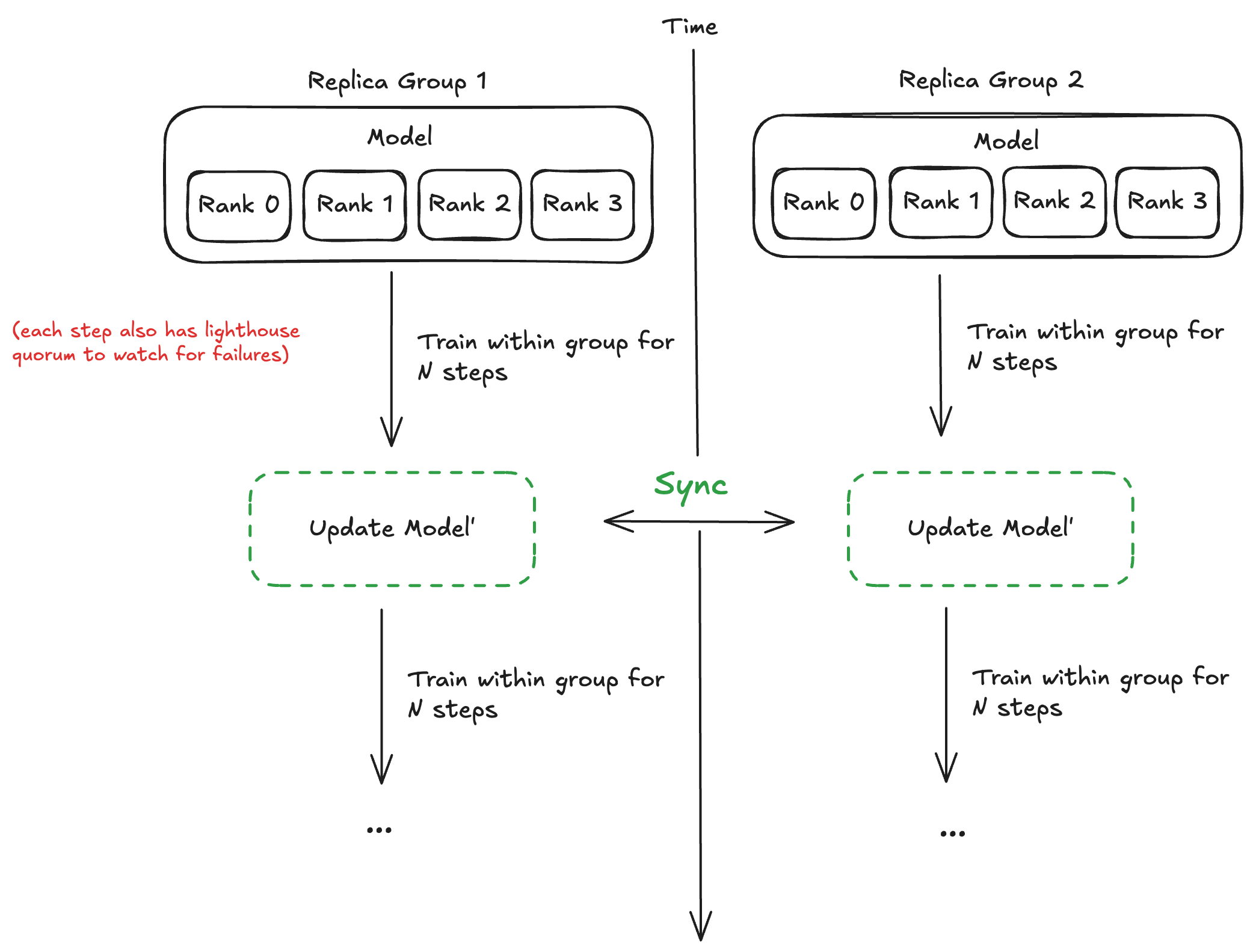
When integrating with TorchTitan we wrapped the entire training loop with these context managers. To handle the failure case, these algorithms also need to load the correct weights when recovering. For LocalSGD we can simply recover the weights from another currently training replica group. For DiLoCo, we need to start the model weights from the point of the last global model weights.
If TorchTitan uses FSDP or TP as its parallelism strategy, then it converts the model parameters into DTensors. We also needed to account for this parameter change because if it is a DTensor we only want to exchange and synchronize the local shards of that tensor.
Results
Here is a screen recording of a simple UI built to demonstrate using torchtitan on 2 replica groups. We also have a separate process running the lighthouse server. The demo progresses as follows:
- Start lighthouse server
- Start replica group 1, allow it to train for a bit
- Start replica group 2, retrieves the state dict from group 1 and starts training
- Kill replica group 2
- Replica group 1 recovers and continues training

We also ran this for multiple hosts on our internal servers for LLama3 8B. We see similar MFU across the runs. With DiLoCo, we see slightly higher memory usage (+4%) which is expected because DiLoCo needs to keep a copy of its local shard of model parameters from the previous global update.
Next steps
There are some clean up improvements that we could do for the torchft integration with torchtitan. We also can support and better test other process group variants in torchft. We can polish and land the UI as a beginner-friendly way to run torchtitan. There are improvements to the DiLoCo algorithm that can be added, for example supporting streaming DiLoCo.