With Tianyu Liu (@tianyu), Chien-Chin Huang (@fegin), Wei (Will) Feng, Gokul Nadathur (@gnadathur)
TL;DR
We enabled FLUX.1 model suite large-scale pre-training on TorchTitan with FSDP and HSDP support, showcasing diffusion model pre-training on TorchTitan. We also illustrated the training process by running large-scale pre-training using FLUX.1[schnell] model, showing meaningful training results. We showcased the process of onboarding custom models onto torchtitan, empowering the advanced model with TorchTitan’s powerful large-scale training techniques.

Image generated from TorchTitan trained FLUX.1[schnell] model
Distributed with TorchTitan
The GitHub repository torchtitan is a proof of concept for large-scale LLM training using native PyTorch, designed to be easy to understand, use, and extend for different training purposes, supporting multi-dimensional parallelisms with modular components. In this series of topics, we introduce the latest PyTorch features for distributed training enabled in TorchTitan.
- Topic 1: Enabling Float8 All-Gather in FSDP2
- Topic 2: Introducing Async Tensor Parallelism in PyTorch
- Topic 3: Optimizing Checkpointing Efficiency with PyTorch DCP
- Topic 4: Training with Zero-Bubble Pipeline Parallelism
- Topic 5: Breaking Barriers: Training Long Context LLMs with 1M Sequence Length in PyTorch Using Context Parallel
- Topic 6: Semi synchronous training in combination using TorchFT
- → Topic 7: FLUX is Here: Experience Diffusion Model Training on TorchTitan
Onboard custom models to TorchTitan
TorchTitan’s framework and modular components are crafted to simplify the integration of custom models, enabling you to fully leverage its capabilities for your projects. To optimize the use of this robust framework, we suggest the following steps for your model development lifecycle:
- Select dataset: Begin with data preparation. TorchTitan offers a comprehensive dataloader (link) that seamlessly integrates with various HuggingFace datasets, tokenizers, and data processing functions. Additional examples, such as a multimodal dataloader, are available in the experiment folder (link).
- Model and Training components Definition: Define the model architecture and training components, including loss function, optimizer, learning rate scheduler, etc. Utilize the TrainSpec abstraction (link) provided by TorchTitan to define your model’s training components
- Training Configuration: Create a training configuration to manage the training loop. The components in TorchTitan are designed as reusable blocks that can be toggled on or off via config files. You can use the provided train loop (link) to effortlessly enable advanced training technologies.
- Parallelization Plan: Crafting a parallelism plan tailored to your model is made easier with TorchTitan. You can refer to the comprehensive, all-inclusive Llama3 example (link) for guidance on applying DDP, FSDP, tensor parallelism, and activation checkpointing.
- Performance Analysis and Debugging: Enhance your model’s performance by utilizing existing tools like profiling, and deterministic training options. This step is crucial for model performance but you can get it done by simply incorporating existing tools provided by TorchTitan.
We will publish a thorough guidance for adding new models in TorchTitan, with more details explained. Following the above brief path, we introduced FLUX model, the state-of-the art diffusion model onto TorchTitan as a step-by-step example:
- FLUX.1 Dataset and Processing: We adapted the dataloader logic for the CC12M dataset, adding a function for customized processing. Images were standardized to 256 x 256 pixels by resizing, cropping, and filtering to ensure quality.
- FLUX.1 Model and Training Components Definition: The model architecture is integrated from the open-source version (github), and we use the MSE loss function for training.
- FLUX.1 Training Config and Loops: Developed three training configurations to control the loop, with minor adjustments to the forward-backward step by extending the main trainer class.
- FLUX.1 Parallelization Function: Designed an FSDP plan based on Llama practices, applying FSDP to the T5 encoder and FLUX.1 model.
- Training, Performance Analysis, and Debugging: Optimized the FLUX.1 model on TorchTitan, reducing training time through detailed process analysis.
In the following sections, we will dive deeper into the FLUX.1 model on TorchTitan, discussing design choices to provide more insight about onboarding models, as well as showcasing diffusion model training on TorchTitan.
Diffusion model and FLUX.1 model
Diffusion models are a class of generative models that have gained popularity for their ability to generate high-quality data, such as images, by simulating a diffusion process. Diffusion models work by gradually transforming a simple, structured distribution (like Gaussian noise) into a complex data distribution (such as natural images) through a series of small, reversible steps[1]. This transformation is typically modeled as a stochastic process, where each step adds a small amount of noise to the data, and the model learns to reverse this process to generate new samples. In recent years, the diffusion models has been proven to be very effective in generating high-resolution images[2] and videos[3],
FLUX.1 model is the state-of-the-art diffusion model, developed by Black Forest Labs. FLUX.1 is a suite of text-to-image models that define a new state-of-the-art in image detail, prompt adherence, style diversity and scene complexity for text-to-image synthesis[4]. From the FLUX.1 model suite, Black Forest Lab open-sourced FLUX.1[dev] and FLUX.1[schnell] models. Our work is based on the open-sourced version (github). For more information about FLUX.1 model suite, please refer to the blog (link) from Black Forest Labs.
FLUX.1 Model on TorchTitan
Now the FLUX.1 Models are available on torchtian, supporting pre-training from scratch.
What feature we support:
- Parallelism: The model supports FSDP, HSDP for training on multiple GPUs. The FLUX.1 models are using TorchTitan compatible architecture, ready to integrate more parallelism.
- Activation checkpointing: The model uses activation checkpointing to reduce memory usage during training.
- Checkpointing: save and load DCP format checkpoint.
- Classifier-free diffusion guidance support: We support classifier-free guidance for FLUX.1 models.
We support 3 different flavors of FLUX model:
- Debug model: smaller-size model (~0.25B), used mainly for local debugging on TorchTitan
- FLUX.1 [dev]: FLUX.1 [dev] is an open-weight (link), guidance-distilled model, with ~12B parameters.
- FLUX.1 [schnell]: FLUX.1[schnell] is the open-sourced, fastest model that is tailored for local development and personal use. This model has ~12B parameters.
FSDP
In this section, we will analyze FSDP performance on the FLUX.1 [schnell] model. In the profiler shown below, the FLUX model is sharded across 8 GPUs (Local batch size = 64, FSDP shard degree = 8, other detailed parameters can be found here). The FLUX.1 [schnell] model consists of 19 SingleBlocks (a transformer-based layer), and 38 DoubleBlocks, we wrapped each block as a separate FSDP module. For linear layers and Multi-Layer Perceptron (MLP) blocks, we also wrapped each layer into separate FSDP modules.
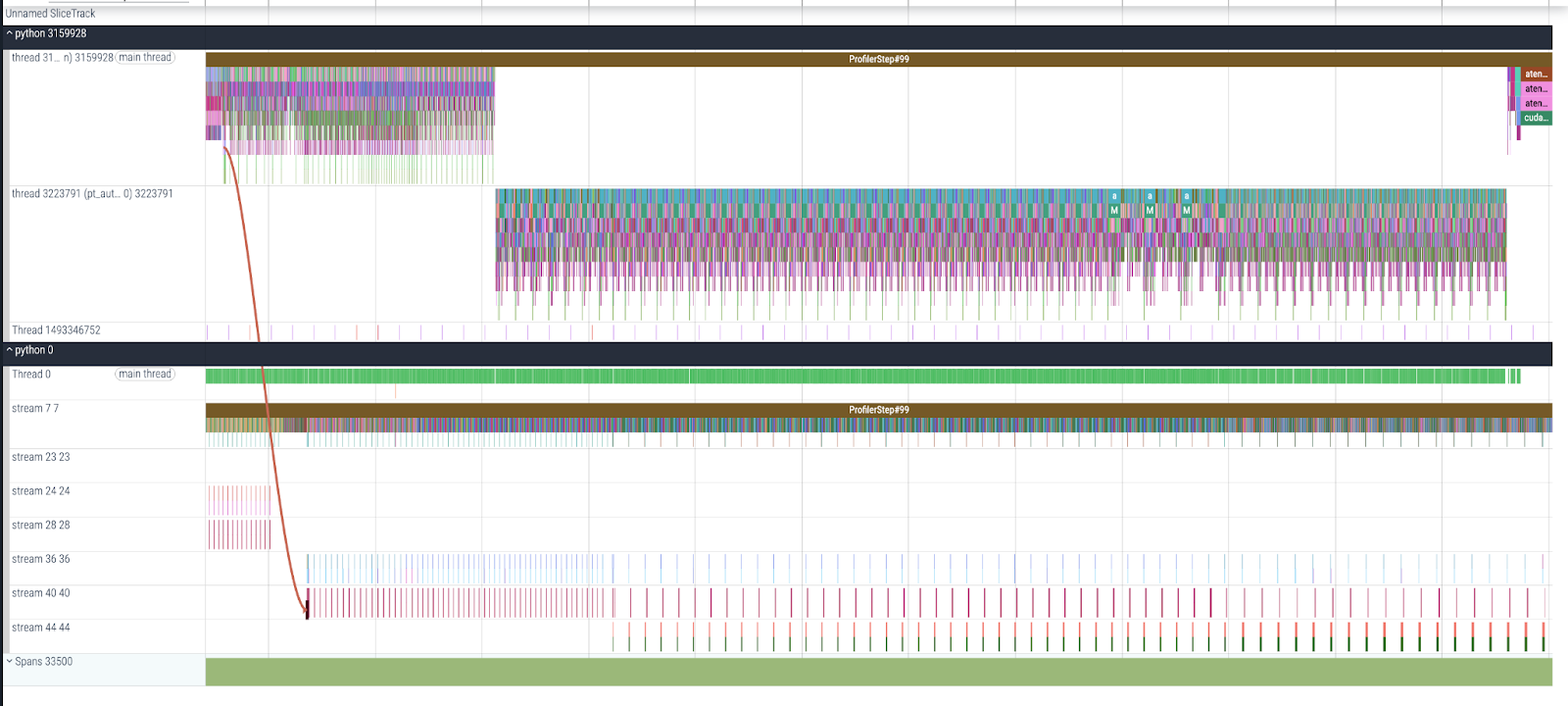
Fig 1. Overview of FLUX.1[schnell] model profiler performance w/ FSDP
The above diagram shows the forward pass and the backward pass of FLUX.1[schnell] model, it shows communication-computation overlapping with FSDP applied.
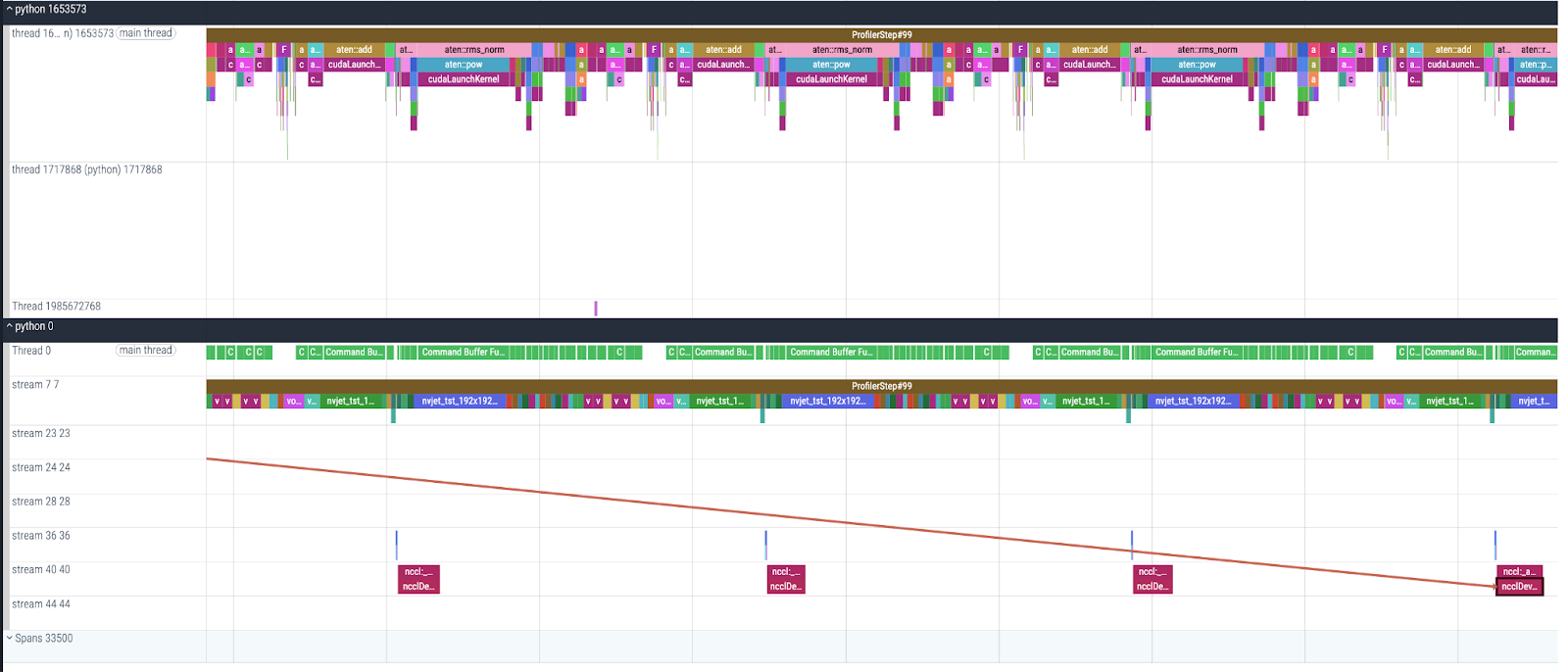
Figure 2: Detailed examination of the forward pass performance of the FLUX.1[schnell] model
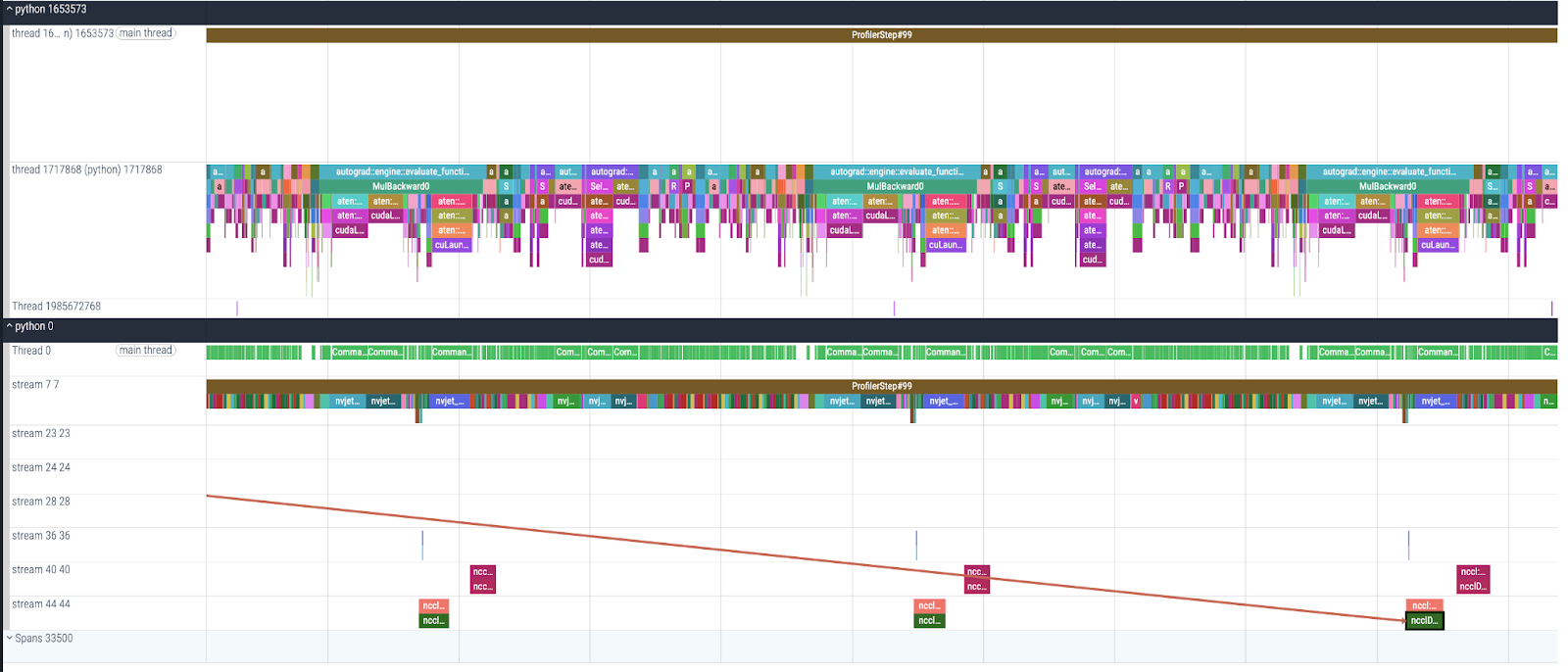
Figure 3: Detailed examination of the backward pass performance of the FLUX.1[schnell] model
Activation Checkpointing
To further mitigate peak GPU memory usage, we used activation checkpointing to reduce the GPU memory usage associated with activations. Activation checkpointing selectively drops these activations and recalculates them on-the-fly, which uses more computation in exchange for lower GPU memory. For the FLUX.1 model, the T5 text encoder generates an encoding with a hidden dimension of 4096, which is subsequently processed by the FLUX.1 model, resulting in huge activation size during forward pass calculations. In this context, the tradeoff between GPU memory and computation is justified. Specifically, for each single block and double block within the FLUX.1 model, we store activations at the block level and recompute all intermediate results within each block. During the backward pass, we load the input activations for each block and recompute intermediate activations prior to computing gradients.
Sharded Encoder
The FLUX.1[schnell] model uses the output of multiple pretrained, frozen networks as inputs, including autoencoder latents and 2 text encoder representations: CLIP L/14 model[5] based text encoder (link), and T5-v1.1-xxl[6] text encoder (link). The CLIP L/14 model was originally developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The CLIP text encoder will generate a text representation for each prompt with length 768. The T5-v1.1-xxl text encoder is based on the T5 pre-trained model, with ~11 billion parameters, and it generates a text representation with shape 256 * 4096 for each input prompt.
The computation for CLIP text encoders is relatively low. Applying FSDP to the CLIP text encoder will introduce significant communication overhead, resulting in idle periods (“bubbles”) that slow down end-to-end training. In contrast, the T5 encoder involves more substantial computations, so the communication brought by FSDP can be hidden by computation. In our training, we opt to parallelize the T5 text encoder across GPUs using FSDP, while maintaining a full copy of the CLIP text encoder on each GPU.
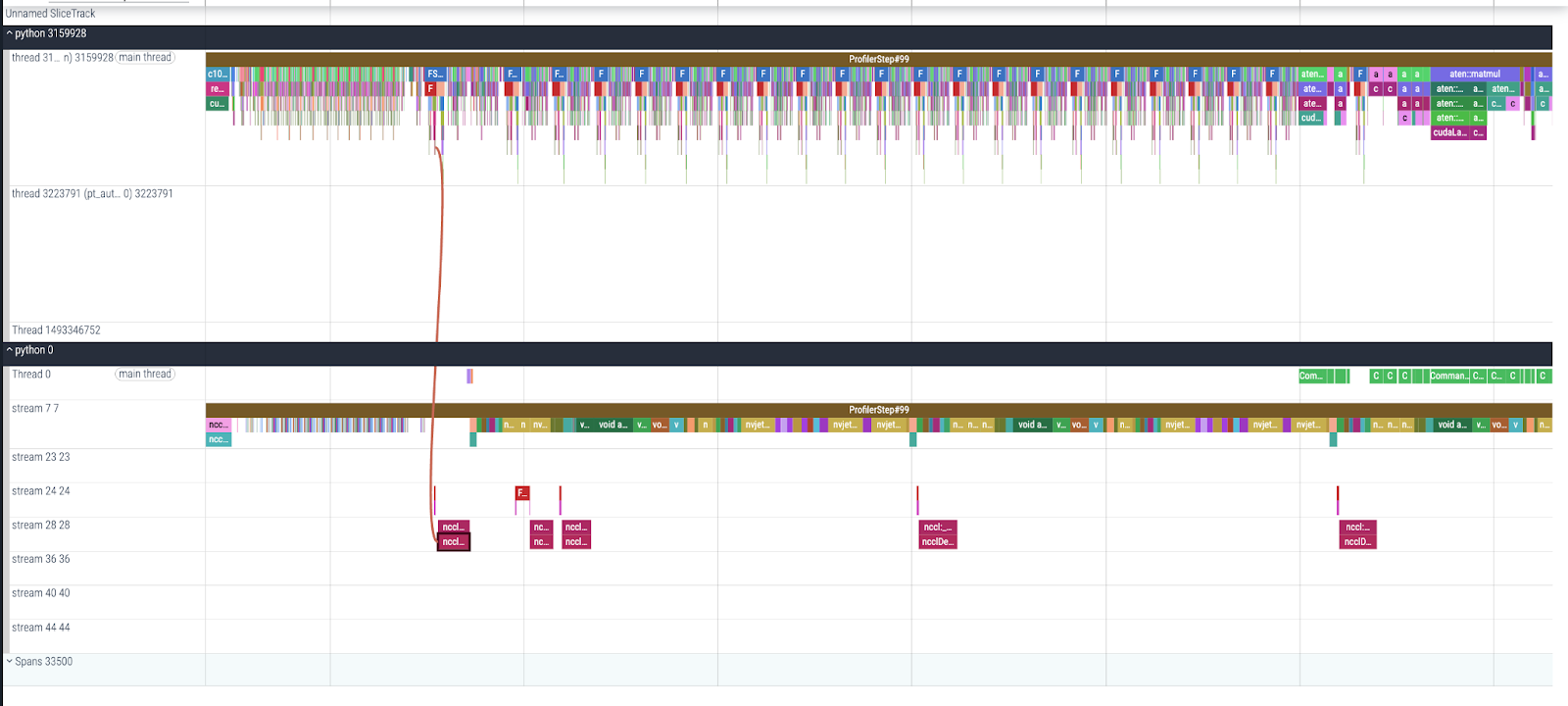
Fig 4. FSDP all-gather collectives from T5 encoder are overlapped except the first one
Data Preprocessing
In FLUX.1 model training, the text input will be encoded into encodings by 2 pre-trained, frozen text encoders: T5 text encoder and CLIP text encoder. The input image will also be encoded into latent space using frozen Variational AutoEncoder (VAE), and the VAE weights are loaded from the open-sourced version from Black Forest Labs). This process is shared by all training runs, thus we could save end-to-end time by saving the pre-calculated encodings. We supported data preprocessing in TorchTitan. During preprocessing, the text encodings from 2 encoders are saved and written to disk. For the image encoder, instead of saving the encoded image latents, we save the mean and logarithmic variation of VAE. This is in order to still perform the usual behaviour of an VAE, where latents are not deterministically produced, but rather sampled from a Gaussian which it parametrizes.
One caveat is that the preprocessed data might take up a huge storage space, mainly because the generated t5 encoding is huge, with shape (seq_len, 4096). To fully store the preprocessed 12 million data samples from CC12M dataset with sequence length 256, it needs more than 12TB only for T5 text encodings. In our end-to-end training, we didn’t apply data preprocess because of the enormous storage it would take.
End-to-End Training on TorchTitan
We also performed a large-scale pre-training of the FLUX.1[schnell] model, with TorchTitan implementation. In this training, we leveraged the open-source dataset Conceptual 12M (cc12m-wds), which was originally developed and described in this paper. Conceptual 12M (CC12M) is a dataset with 12 million image-text pairs specifically meant to be used for vision and-language pre-training.
Training setup
| Parameters | |
|---|---|
| Steps | 40k |
| Batch size | Local batch size = 16, global batch size = 2048 |
| Parallelism setting | dp_shard_degree = 8, dp_replicate_degree = 16 (total 128 GPUs) |
| Lr_schduler setting | Warmup step = 30k, no learning rate decay after stable stage. Max learning rate = 1e-4 |
| Classifier free guidance setup | In training: dropout rate is 0.447, train unconditional model on ~20% data samples. In inference: classifer_free_guidance_scale = 5.0 |
We have proposed this training setup based on relevant research[7] utilizing the CC12M dataset. The FLUX.1[schnell] model was trained using a total of 128 GPUs, with a global batch size of 2048. We also encourage users to explore the training setup with better performance using torchtitan. It is important to note that our end-to-end training employed only a portion of the CC12M dataset, rather than the complete dataset, due to an issue (link) in the dataloader. Subsequent runs have demonstrated a similar trend in loss convergence, indicating that the results here are meaningful and representative.
Training loss curve
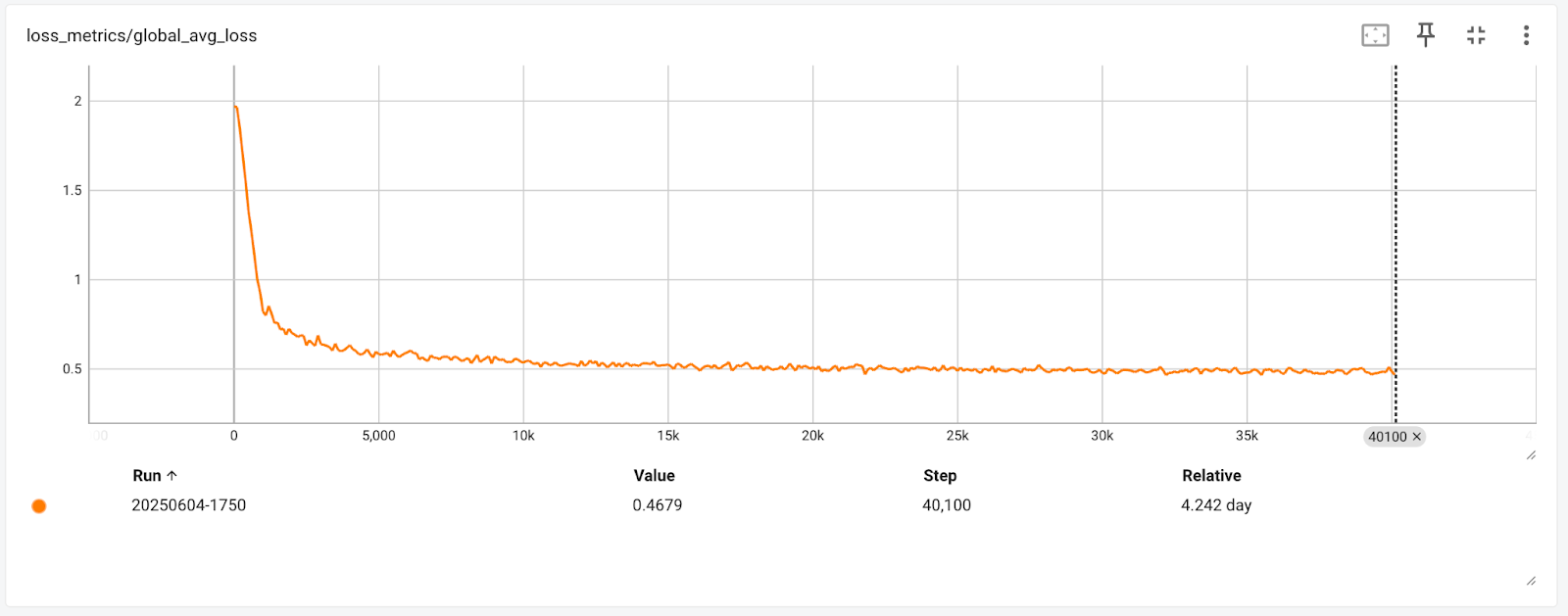
Fig 5. FLUX.1[schnell] model Training loss curve
We reported the training loss in Figure 5, which still shows a slight downward trend. This indicates that the model is continuing to learn and improve, and not fully converged yet. Due to computational resources and time constraints, we have only showcased the initial results, focusing on the convergence and correctness of the FLUX.1 model pre-training on TorchTitan. The training loss shown in Figure 3 represents the average loss across different noise levels during the diffusion steps within a training step. The averaged training loss would indicate the overall convergence level but might lack a detailed look at specific noise level.
To further enhance our evaluation, we are in the process of implementing validation loss measurements (as mentioned in paper) on a separate validation dataset. This will allow us to better assess the training process by providing insights into the model’s generalization capabilities and its performance on unseen data.
Inference Results at different steps

Fig 6. Inference result from TorchTitan trained FLUX.1[schnell] model
From the visualization results above, the trained FLUX.1 model could generate meaningful images based on the given prompt, with great details, such as “cherry blossoms” and “reflecting golden sky.” These results demonstrate the model’s ability to interpret and render complex scenes with impressive accuracy and aesthetic appeal. However, for some of the longer prompts, it failed to capture certain details. For example, when given the prompt “A space station orbiting a colorful nebula,” the model produced an image of a nebula but lacked details of a space station. This limitation might be attributed to insufficient training steps in our experiments, which could prevent the model from fully learning the nuances of more complex prompts. Additionally, the underlying distribution of the CC12M training dataset may have intrinsic differences from the given prompts, leading to a mismatch in the model’s ability to generalize to unseen or less frequent scenarios.
To address these challenges, future work could involve extending the training duration, diversifying the training dataset, or incorporating additional data augmentation techniques to better align the model’s learning process with the desired output characteristics. Furthermore, fine-tuning strategies could enhance the model’s capacity to handle intricate and detailed prompts more effectively.
Next Step
In the next phase, we plan to improve the training of the FLUX.1 model in TorchTitan mode by adding more parallelism and features to ensure a seamless and user-friendly experience. Additionally, we aim to expand the use of FLUX.1 TorchTitan in collaboration with the open-source community.
- We collaborated with MLCommons and NVIDIA to develop the MLPerf training reference implementation for FLUX.1. This benchmark (link) will be part of the MLPerf Training benchmark suite soon.
- Expanding Parallelism Support: We plan to extend the current FSDP/HSDP parallelism framework to include parallelisms such as Tensor Parallel and Context Parallel.
- Adding validation support: We will support diverse evaluation metrics for the FLUX.1 model on validation dataset, such as the validation loss, CLIP score, and FID score.
- Adding torch.compile support: We will enable support for torch.compile on the FLUX.1 model to optimize performance and efficiency.
Acknowledgment
- We would like to express our gratitude to Black Forest Labs for their significant contributions to the onboarding of FLUX to TorchTitan. Their technical expertise and collaborative efforts were instrumental in facilitating a successful integration and benefiting open-source users, and we are grateful for their support throughout this process.
- We deeply appreciate MLCommons and NVIDIA for their exceptional technical expertise and collaborative spirit, which played a crucial role in achieving a seamless integration. Their support has significantly benefited the open-source community, and we are thankful for their dedication throughout this journey.
Song, Y., Sohl-Dickstein, J.N., Kingma, D.P., Kumar, A., Ermon, S., & Poole, B. (2020). Score-Based Generative Modeling through Stochastic Differential Equations. ArXiv, abs/2011.13456. ↩︎
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2), 3. ↩︎
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., … & Taigman, Y. (2022). Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792. ↩︎
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PmLR. ↩︎
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140), 1-67. ↩︎
Gu, J., Zhai, S., Zhang, Y., Susskind, J. M., & Jaitly, N. (2023, January). Matryoshka diffusion models. In The Twelfth International Conference on Learning Representations. ↩︎